Anti-Patterns in Microservice Development Common Pitfalls and How to Avoid Them
Microservices are a very robust and powerful architecture choice, and nowadays, several prestigious software companies are built with it. Still, very frequently, developers commit some very common mistakes that may compromise performance, scalability, and costs. And, in this article, we will discuss these a bit further, explain such errors, and understand how to avoid them. Stay tuned and learn a bit further how to avoid these!
What Are Microservice Anti-Patterns?
In the context of software development, anti-patterns are technical decisions during development time that seem at first beneficial and efficient, but in the long term will lead to problems in the code. Such implementations usually violate the core principles of the microservices architecture – such as loose coupling, independent deployment, and scalability. It creates technical debt, operational bottlenecks, and instabilities.
These anti-patterns usually appear because they seem faster to implement in the short term, mimic patterns from monolithic systems without proper implementation, and because teams underestimate the complexity of distributed systems. So, these architectural traps can silently turn your microservices into slow, fragile, and expensive-to-maintain different monoliths, making the very idea of using this architectural concept.
To digress a bit further, when a company adopts microservices, the goal is to tear the system down into smaller subsets in order to achieve different goals. They are, among others:
- Flexibility: Upgrading one service shouldn’t compromise another one, hence making each of them more flexible. This means that you can, for instance, create “main” services to host the most important parts of your project, while with “satellite” services, you can test, create, and expand your business.
- Scalability: As each service is responsible for a different set of features, it is easier to scale the most used ones while keeping the least important small, potentially saving you a lot of money in cloud expenses.
- Speed: Since everything’s neatly organized, it becomes easier and faster to develop new features and ship code to production. That’s crucial for gaining traction in the market and expanding your business, as in the current day, the company that better adapts to new standards and innovates faster will excel over the competition.
And now, let’s understand how to recognize such anti-patterns and understand when they’re hurting your code and your company as a whole.
How to Recognize Anti-Patterns In Your Business
Even though microservices promise faster innovation, scalability, and resilience for your project, it is not a guarantee. When your code is “infected” with it, your company as a whole will suffer – development becomes slower and more confused, bugs proliferate, and it becomes more and more expensive to maintain. Here are some of the common symptoms of this disease to help you diagnose it in your business:
- Operational costs rise steadily: Each anti-pattern implemented adds hidden complexity to the system. Because of them, there are more services to maintain, more integrations to understand, and more infrastructure overhead. All of it, then, becomes a drain on your engineering resources, and it will surely add up and lower your margins.
- Agility slows down: Tight coupling between services or poorly designed dependencies makes new features harder to deliver. It will slow down your sprint times, raising the delay in innovations, as developers are stuck in deployment cycles that are disturbed by “code entanglement.” That is, if your devs can no longer deliver code fast, they are probably quite literally scrambled in the codebase and can’t find a way out to innovate.
- Quality and reliability decline: When systems are fragile, even the smallest changes can cause cascading failures. It will result in bigger downtimes, frustrated users, and potential revenue loss, as churn rates soar with the growing chaos.
- Talent frustration and turnover: Developers don’t want to fight an overcomplicated, brittle system. Such a degree of technical debt will burn them out, as the stress is immense for so little progress to be made. It will, then, be harder to attract and retain skilled engineers, making it so that no developer knows how the system works, as all of them leave as soon as they start to get stressed before even understanding it.
From a commercial standpoint, every microservice anti-pattern is a cost multiplier, increasing expenses, slowing innovation, and risking your reputation. You must understand that, in the end of the day, the product that your user base navigates (and buys) results from the code you have developed, and, if such code is bad, your customers will be stressed and possibly churn. It will surely create havoc in your business, leading to plummeting KPI’s.
Common Anti-Patterns in Microservice Development
Now, let’s finally delve a bit further into what exactly these anti-patterns are and the actual effects of their existence in a codebase, to help you better avoid them.
The Distributed Monolith
As one of the most common problems in the creation of microservices, it happens when they aren’t properly planned before being coded. It’s a lack of properly thought-out software architecture, which ends up in a “disguised monolith” – services are still highly coupled and with rigid dependencies, not being really “micro”. From it stems several problems, such as broken deploy pipelines, a reduction in the accuracy of tests, and overly expensive and complicated scalability, and all of it severely diminishes the reliability of the system. That’s the issue that makes the code the most complicated to maintain, understand, and debug, and overall complicates the lives of developers, stopping them from progressing with the code.
Over-Engineering the Architecture
The opposite of the previous problem is also a problem: it is bad to create a loosely distributed monolith, but it’s also bad to over-engineer this architecture and create unnecessary microservices. They will raise complexity and make it very difficult to keep track of what exactly each service does, and also raise your cloud expenses by keeping so many different systems running simultaneously.
Shared Database Between Services
Creating a shared database for connecting different microservices is very often just plain nonsensical. It goes directly against the very reasons why this architecture was created in the first place, and will surely make its functioning much more fragile and unreliable. It breaks the principle of independence between the services, as they all source their data from the same database. Also, as all of them have the same source of information, should anything happen with it, all the services will break at the same time. So, at the end of the day, it works more or less like a monolith, completely breaking the reason to adopt microservices.
Chatty Services and Excessive Network Calls
As microservices are entirely different systems but still need to communicate, they must use network calls to send messages and tell other services what to do. It usually happens through queues, such as AWS’s Simple Queue Service (SQS) or others. But when systems are overcommunicating and sending too many messages, it may cause latency and bottlenecks in the processes, leading to a slower user experience, which usually results in user dissatisfaction. That’s usually a sign that the communication wasn’t very well planned and that unnecessary data is being sent between services, and thus it must be very carefully reviewed and refactored.
Neglecting Security in Inter-Service Communication
That’s a problem that might even put your whole user base at stake, as it compromises the security of your application. It happens when the traffic communication between services is not authenticated or encrypted. It opens a huge gap through which malicious users may be able to intercept messages and hijack the functioning of your service, exploiting its database to steal sensitive data, and even delete/edit your customers’ data. It is of extreme importance that this communication is as well-encrypted as possible, as very sensitive information can run through traffic, potentially exposing your most important asset — your database.
Architecture Reference: Bounded Contexts & Service Contracts
Here’s a quick visual example of the difference it makes when you properly apply design patterns during microservice development. The system works more fluidly, and every service has a clear, well-structured role.
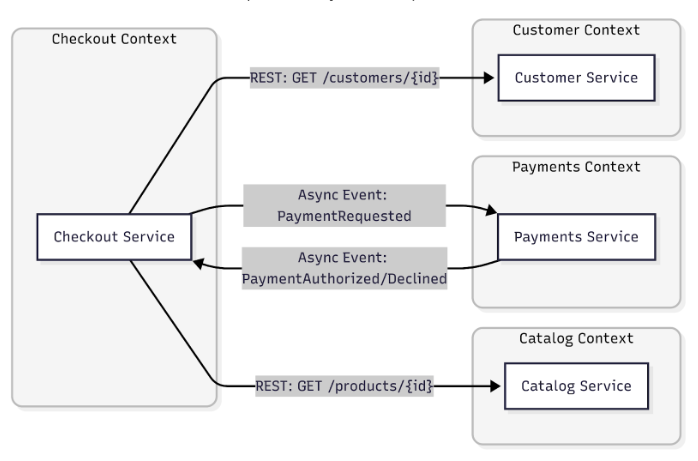
Bounded Contexts (DDD) & Ownership
This diagram shows how each service must belong to a clear, specific domain context (for instance: Checkout, Catalog, Payments, Customer). Each context has its own logic and database; communication between services is made using explicit contracts (such as REST APIs or events), and everything is well-organized and divided. This avoids the shared database anti-pattern, fostering autonomy between services.
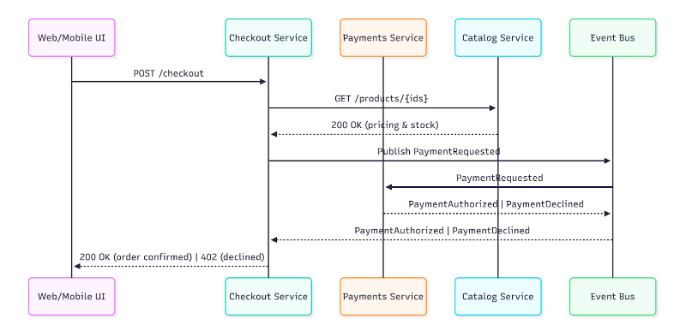
Event-Driven Checkout Flow (Anti-chatty, resilient)
This sequence diagram shows an event-driven checkout flow, in which the Checkout service orchestrates the purchase, but delegates tasks to other services:
- The customer starts an order in the Checkout Service.
- The Catalog Service provides product information and stock levels.
- The Checkout publishes the PaymentRequested event to the system message bus.
- The Payments Service processes the payment and returns the response as an event (PaymentAuthorized or PaymentDeclined)
- The Checkout receives the event and responds to the customer.
This pattern avoids the chatter problem, preventing excessive synchronous calls between services, and also fosters resilience – if Payments goes down for a few seconds, the system can automatically recover as soon as the service is back online.
How to Avoid Microservice Anti-Patterns
To avoid having your system fall into anti-patterns, you must build a disciplined architecture mindset from day one and ensure that your whole team also follows the concept to the letter. One of the keys is to adopt best practices that keep services independent, maintainable, and resilient over time.
Some of the core strategies you can use are:
- Embrace Domain-Driven Design (DDD): Create services around the business domain rather than technical layers. It will reduce coupling and ensure each service reflects a clear context with its logic and data.
- Favor asynchronous communication: Use message queues or event-driven architecture instead of direct, synchronous calls wherever possible. This reduces latency and prevents cascading failures when there’s a problem with any service.
- Review and refactor regularly: Schedule regular reviews to detect anti-patterns early and refactor before they become too costly.
- Invest in observability: With centralized logging, distributed tracing, and metrics, you can properly understand where exactly an error happened. Observability is critical for diagnosing issues quickly and preventing minor problems.
- Model by Domain: bounded contexts & aggregates: Avoid having shared “global entities”. Each context has its own persistence layer. With this, each service can keep evolving while not prejudicing the other ones. Here’s an example with Prisma models:
// apps/catalog/prisma/schema.prisma
model Product {
id String @id @default(cuid())
sku String @unique
name String
priceCents Int
stockQty Int
updatedAt DateTime @updatedAt
}
// apps/checkout/prisma/schema.prisma
model Order {
id String @id @default(cuid())
customerId String
totalCents Int
status OrderStatus @default(PENDING)
createdAt DateTime @default(now())
}
enum OrderStatus {
PENDING
PAID
DECLINED
}
With this, each service has its own models and can develop without requiring modifications in other services.
- Prefer Async first: events over synchronous calls: It reduces chatter and aggregate latency, improving resilience against network interruptions and making your application smoother overall.
Publish “PaymentRequested” event (Kafka/SQS-agnostic) with TypeScript:
// checkout/src/paymentPublisher.ts
type PaymentRequested = {
event: "PaymentRequested";
version: 1;
data: { orderId: string; totalCents: number; customerId: string };
};
export async function publishPaymentRequested(
bus: { publish: (topic: string, msg: unknown) => Promise },
payload: PaymentRequested["data"]
) {
const message: PaymentRequested = {
event: "PaymentRequested",
version: 1,
data: payload,
};
await bus.publish("payments", message); // Kafka topic / SQS queue
}
Payments Service consumer with Python:
# payments/consumer.py
from typing import TypedDict
class PaymentRequested(TypedDict):
event: str
version: int
data: dict
def handle_payment_requested(msg: PaymentRequested, gateway):
order_id = msg["data"]["orderId"]
amount = msg["data"]["totalCents"]
approved = gateway.authorize(amount)
event = {
"event": "PaymentAuthorized" if approved else "PaymentDeclined",
"version": 1,
"data": {"orderId": order_id}
}
bus.publish("checkout", event)
- Design clear, versioned APIs (REST + OpenAPI): By designing versioned contracts, you can make independent deploys, requiring less coordination between teams and allowing for faster development cycles. Here’s an example of a contract created with OpenAPI for our Payments service:
openapi: 3.0.3
info:
title: Payments API
version: 1.0.0
paths:
/v1/payments/authorize:
post:
summary: Authorize a payment
requestBody:
required: true
content:
application/json:
schema:
type: object
required: [orderId, totalCents]
properties:
orderId: { type: string }
totalCents: { type: integer, minimum: 1 }
responses:
'200':
description: Authorization result
content:
application/json:
schema:
type: object
properties:
authorized: { type: boolean }
authId: { type: string, nullable: true }
- End-to-End Observability (logs, metrics, tracing): It can lead to faster diagnostics, foster data for SLO/SLI, and lead to a lower MTTR, while making your application easier to debug and understand.
// payments/src/otel.ts
import { NodeSDK } from "@opentelemetry/sdk-node";
import { getNodeAutoInstrumentations } from "@opentelemetry/auto-instrumentations-node";
import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-http";
export const sdk = new NodeSDK({
traceExporter: new OTLPTraceExporter({ url: process.env.OTLP_URL }),
instrumentations: [getNodeAutoInstrumentations()],
});
// index.ts
import { sdk } from "./otel";
sdk.start().then(() => {
// start HTTP server / consumer here
});
Structured logs:
// payments/src/logger.ts
export const log = (level: "info"|"warn"|"error", msg: string, ctx: Record<string, unknown> = {}) =>
console.log(JSON.stringify({ level, msg, ts: new Date().toISOString(), ...ctx }));
- Resilience by Default: Implement circuit breakers, retries, and timeouts to avoid cascading failures and keep the user experience graceful degradation. Here’s an example with Spring Boot and Resilience4j:
// catalog-client/src/main/java/com/acme/catalog/CatalogClient.java
@FeignClient(name = "catalog", url = "${catalog.url}")
public interface CatalogClient {
@GetMapping("/v1/products/{id}")
ProductDto getProduct(@PathVariable String id);
}
// checkout/src/main/java/com/acme/checkout/ProductGateway.java
@Service
public class ProductGateway {
private final CatalogClient catalog;
public ProductGateway(CatalogClient catalog) { this.catalog = catalog; }
@CircuitBreaker(name = "catalog", fallbackMethod = "fallback")
@Retry(name = "catalog")
@TimeLimiter(name = "catalog")
public CompletableFuture get(String id) {
return CompletableFuture.supplyAsync(() -> catalog.getProduct(id));
}
- Contract tests: It avoids invisible entanglement between services. With this pattern, if the provider breaks the contract, then your CI pipeline will warn you before deploy time. Here’s an example with PactJS:
// checkout/test/payments.pact.test.js
const { Pact } = require("@pact-foundation/pact");
const { like, integer, boolean } = require("@pact-foundation/pact").Matchers;
const fetch = require("node-fetch");
describe("Payments contract", () => {
const provider = new Pact({ consumer: "Checkout", provider: "Payments" });
beforeAll(() => provider.setup());
afterAll(() => provider.finalize());
test("authorize payment", async () => {
await provider.addInteraction({
state: "payment can be authorized",
uponReceiving: "a request to authorize",
withRequest: {
method: "POST",
path: "/v1/payments/authorize",
body: { orderId: like("ord_123"), totalCents: integer(1000) },
headers: { "Content-Type": "application/json" }
},
willRespondWith: {
status: 200,
headers: { "Content-Type": "application/json" },
body: { authorized: boolean(true), authId: like("auth_abc") }
}
});
const res = await fetch(provider.mockService.baseUrl + "/v1/payments/authorize", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ orderId: "ord_123", totalCents: 1000 })
});
expect(res.status).toBe(200);
});
});
By embedding these practices into your development culture, you safeguard your investment in microservices development, enabling lower maintenance costs, faster delivery, and a system that scales with your business goals. And with this, you can enjoy the benefits of this very powerful architecture, as your system will be ready to scale and take on the always more competitive market.
Implementation Checklist for a Healthy System
- ✅ Domain contexts and banks divided by services (no shared databases);
- ✅ Versioned APIs + contract tests in the CI;
- ✅ Asynchronous events for more critical inter-service integrations;
- ✅ Resilience: timeout, retry, circuit breaker, fallback;
- ✅ Observability: structured logs, metrics, tracing;
- ✅ Security: mTLS/JWT between services, managed secrets.
Following these steps, you can reduce operational costs, accelerate releases, and minimize incidents, making your product more reliable and failure-proof.
The ROI of Healthy Microservice Practices
Good microservice architecture isn’t just about clean code – it’s a strategic investment that delivers measurable business returns. When you follow healthy microservice practices, you will gain both technical excellence and commercial advantage, gaining momentum and quickly leveraging in the marketing to surpass your competition.
With this, you will take advantage of faster time-to-market, improved scalability, reduced incident costs, and optimized resource utilization, among others. And that will result in a project well-architected and well-made, that simply works and that makes sense to be used by your customers, resulting in higher satisfaction and retention, directly impacting your KPIs.
Healthy microservice practices pay for themselves many times over. The investment in disciplined architecture and processes is recovered through lower operating costs, increased agility, and a stronger market position. And, if you perhaps need assistance to implement microservices healthily in your company, you can contact consultancies to help you, such as we at Chudovo – click here to tell us your demand and get a no-obligation quote for your project!
Conclusion
So, to sum things up, microservices are no magic solution nor silver bullet to fix every problem your project might face. If it isn’t well-architected, built, and coded, it will, on the contrary, bring you more and more problems – the system will become more complex to maintain, your cloud expenses will grow rapidly, and the problem will spread and eventually harm the user base.
It is, then, of utmost importance to avoid falling into carelessness and implement anti-patterns in the system that might even be the main basis of your product. Among others, the most common ones are having a shared database between services, having chatty services with excessive network calls, and creating distributed monoliths. All of them stem from, more or less, the same mistakes: not caring enough about the architecture and integrity of the code, the domain, and the product as a whole.
So, in case you already have problems with a not-so-well-made old code base, or want to prevent having one in the future, and rest assured that your product is going to be well built, contact us at Chudovo. We are a consultancy with almost two decades of experience in the market and have already completed hundreds of successful projects all over the world, and we are eager to help develop your project!