What Is DeepSeek And Why It Has Taken The Market Suddenly
The state-of-the-art AI model DeepSeek-R1 was released just last week, but it has already taken the market by arrest. But how and why? Understand here!
The AI market is one of the most volatile and full of speculation in recent years. Companies like OpenAI, Anthropic, and Meta have raised several hundred million dollars, and countless models have been created in the past three years. It has made stocks of many companies, and Nvidia most of all, skyrocket and surpass the mark of trillions of dollars of market value. Also, the AI revolution has made breaking changes in the tech market because of everything it depends on, both technically and in infrastructure. For instance, Microsoft and Meta are making plans to reactivate nuclear plants just to sustain their energy demand; also, AI engineers are amongst the best paid currently.
And, in the past week, a new Large Language Model, called DeepSeek-R1, released by the company Hangzhou DeepSeek Artificial Intelligence, has shaken this market’s foundations. It was thought that AI needed all that infrastructure – both for training the model and to sustain it running, alongside its APIs. This new model, on the other hand, has disproved it: DeepSeek reaches the same accuracy results on benchmark tests as OpenAI o1 while costing a fraction of what it costs. It was also trained on a much more restrained budget than that of OpenAI and other companies, as a side-project for other applications. Now, let’s understand the details of this hype and see how it fares against other models!
How DeepSeek-R1 became this popular
There were many reasons which led to DeepSeek becoming so popular in so little time. It gained so much attention recently that it even suffered several DDoS attacks, going offline and having to halt new sign-ups, along with other malware attacks. So, let’s understand what made it get so much attention.
- It’s disruptive: DeepSeek-R1 was trained in a severely restrained environment, as China has received many sanctions from the US government. This way, the company couldn’t buy Nvidia’s top AI machinery, such as the Nvidia H100 Tensor Core GPU. It’s important to also notice that some AI development libraries are made to only run properly on their GPUs, and they had access to very few of these. So, due to how extreme these conditions were, they had to innovate a lot to train their model, using reinforced learning and techniques to save cost and time.
- It has a great performance: According to the graph published on DeepSeek-R1’s page in Ollama, its benchmarking performance is on par with the current best models, such as OpenAI-o1. The feedback from the users is expressive: these benchmarks seem to hold their position, as users say their performance is sometimes even superior to ChatGPT. Many developers in the community say it’s one of the best models currently for programming, much better than ChatGPT and on par with Claude. DeepSeek also has the great advantage of having a free chat available for online usage, which models like Claude don’t have.
- It’s cheap: Recently, the relatively high costs of LLM usage have shaken the way the SaaS industry works – previously, their profit margins were about 70 to 80%, and now it is around 40 to 50%. Now, DeepSeek has been released costing a fraction of what ChatGPT costs – the first costs $0.15 per million input tokens, while the latter costs $2.50 per million input tokens. That’s a huge saving, cutting expenses by 94%, in an investment that every company nowadays must have to be competitive in the market.
- It nearly crashed the stock market: So big was the fuss around it that the US stock market suffered a crash. Nvidia stocks plummeted around 15% and the AI market has lost more than a trillion dollars already. It happened because many things that were thought to be true were disproved by R1 – such as the infrastructural cost to maintain an LLM running or to train a new one. Sam Altman, CEO of OpenAI, also has publicly admitted to being worried about improving his models and making them cheaper. Also, some leaks from Meta said they are running several simultaneous ‘war rooms’ to study DeepSeek and understand why it’s so good at such a low price point.
So, given how innovative and revolutionary it was in a market already very creative and competitive, DeepSeek has excelled in getting attention and having the leaders worried. And the best part of it is that we, the users, are most benefitted: we can get the best results while also paying less, taking big advantage of the new competition.
How it was trained
Going a little bit deeper into how it was trained and what makes it so innovative, here are some of the practices that they used:
- Reinforcement learning from human feedback (RLHF): Uses deep neural networks for training while also receiving human feedback, creating a reward model to reinforce what was learned.
- Compressing and quantization techniques: It compresses the model, reducing its size while not sacrificing its performance and quality level. A pruning technique was also used to remove less important parts of the neural model, hence reducing its complexity.
- Usage of synthetic data: Uses data generated by other models, reducing cost and time to extract new data from human-made sources. That technique was polemic, as OpenAI has accused DeepSeek of stealing their model’s responses to train their own.
- Transfer learning: Instead of learning from zero, R1 received pieces of information from other previous models. It also means that it was trained on generic tasks to then receive specialized training, reducing cost and time in the process.
- Fine-tuning: The first sets of data generated by the model were labeled and received grades, which helped it become better and more pleasant to human readers.
These practices and some others made R1 a light model that is cheap to use and sustain, while also making sure it had a top-tier performance and quality. Those practices are sure to become commonplace in the industry in the future language models, as the companies are sure to look to release cheaper API prices – as we will discuss further.
How to run it on your computer
As DeepSeek-R1 is an open-source model, it is fairly easy to run locally. Still, of course, as it is an LLM, your computer needs to have good processing – which means that you must either have a good Neural Processing Unit (NPU) or a good Graphical Processing Unit (GPU). If you don’t have either, the computer will run it on your CPU, which will make it work a lot and might not bring you the best response times and quality of response. Still, as R1 is a fairly small LLM (also called Small Language Model), it might bring you better results than other models, due to how cheaply it runs and how well it was trained.
So, to run it, you must first of all install Ollama on your computer. It is an open-source tool created by Meta which is specialized in running LLMs on your machine in a simple and fast way. It is a hub for sharing open-source language models, more or less like GitHub is for the FOSS environment. Also, when you start a model on your computer, it starts listening for requests on your local port 11434, which means that you can use it for API testing or even for local integrations, as we will discuss further.
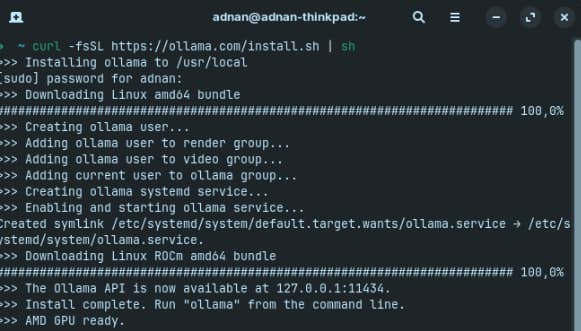
So, if you use Windows or Mac, you can download the installer for Ollama. If, on the other hand, you use Linux, you can install it via the simple command curl -fsSL https://ollama.com/install.sh | sh. Of course, you must have cURL properly installed on your machine – and, if you do, the installation process will begin:
Now, on DeepSeek’s page on Ollama’s website, we will choose the size of the model we want to run – for this example, we will choose the 1.5b parameters, as it’s lighter. So, we must select it, then copy the command to run download the model locally and run it afterward:
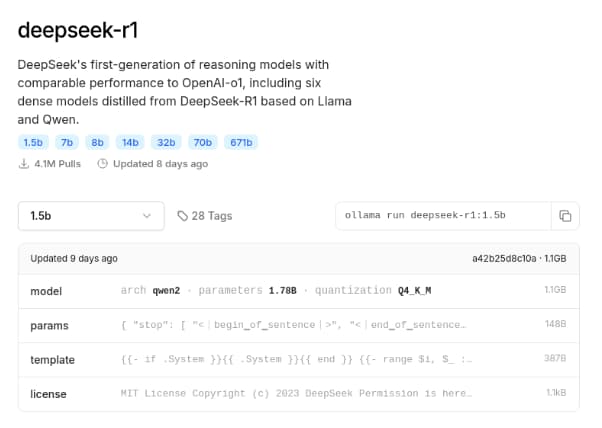
In this case, the command is ollama run deepseek-r1:1.5b.
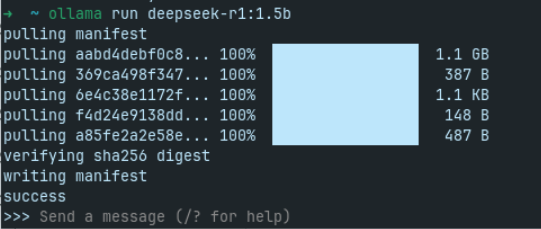
After a quick installation process, we can now start chatting with DeepSeek. An interesting thing is that it shares its thought process and lets us see it in real time before handing out the final answer:

How to integrate it into your API
As is already common in the AI industry, DeepSeek-R1 can integrate with OpenAI’s development tools. So, to take profit from its super-cheap pricing, you can use OpenAI’s libraries, but with DeepSeek’s URLs.
Also, as it is open-source, a very common way to use it in production is to fine-tune your model locally and run it through a Docker instance on your cloud provider. This way, you don’t directly depend on DeepSeek’s servers and pricing lists – you can run it in a private instance on the cloud, which would be cheaper and also more secure for your data. So, here’s a short example regarding the integration into an API environment. Still, in that case, you can’t use OpenAI’s development kits, as it only works with their official API URLs.
Now, here’s a quick example of how to integrate a simple NodeJS and Express project with DeepSeek’s API. Note that this simple tutorial is only about integrating with AI, and thus we won’t teach how to create a new application from scratch.
- Install OpenAI’s libraries to your application
OpenAI has created a specific NPM library to help support their application, and its name is also OpenAI. So, to install it in a Node project, you must run npm install OpenAI, as follows:

- Import the library and create an instance to be used in your application
To do so, you must import OpenAI from OpenAI and create an exported instance of the library, with a baseUrl set to DeepSeek API which uses your apiKey. In case you don’t have a DeepSeek API key, you can apply for one by clicking here.
import OpenAI from “openai”;
export const ai = new OpenAI({
baseURL: “https://api.deepseek.com”,
apiKey: process.env.DEEPSEEK_API_KEY,
});
- Adapt an endpoint to receive the “ai” prompt and send the response
As you can see in the screenshot below, we have set up an example router with a single route, named “example”, which receives a parameter “message” in the body and passes it through DeepSeek API.
import { Router } from “express”;
import { ai } from “../shared/ai”;
const exampleRouter = Router();
exampleRouter.get(“/example”, async (req, res) => {
const { message } = req.body;
if (!message) {
return res.status(400).json({ message: “Message is required” });
}
const response = await ai.chat.completions.create({
messages: [
{
role: “system”,
content: “You are a helpful assistant.”,
},
{
role: “user”,
content: message,
},
],
model: “deepseek-chat”,
stream: false,
})
res.json(response.data.choices[0].message.content);
});
export default exampleRouter;
So, what we do here is call the chat property in the OpenAI object, which itself has a completions property and a create method in it. This create method creates a new message for the API, and receives an array of messages to send. The first message usually has a system hole, defining how the LLM must behave and what it should do: so, the most basic function is to “be a helpful assistant”. Then, the second message has a user hole and it sends the message received from the request. Then we declare what model we want to use, in this case, the “deepseek-chat”, which is the default DeepSeek model their API supports, and set the stream to false, as we want the response to be a single block.
Then, we send back the response to the sender the request with the block response.data.choices[0].message.content. Even though it’s a wordy sentence, that’s the default code: as the API sends back a big reasoning process, that’s the way to extract the first response choice the AI made and retrieve its content. For instance, going a little bit deeper into how these models work, they raise several possible answers to the question sent by the users and only send what they think is the best. So, the choices[0] selects the first answer from the choices array, which contains such possible answers; choices[1] would get the second best, and so on.
The code for this example can be seen by clicking here.

Certified engineers
Convenient rates
Fast start
Profitable conditions
Agreement with
EU company
English and German
speaking engineers
The future of the AI market
As cited previously, the release of DeepSeek-R1 has taken the AI market by arrest. It shook many stock prices all over the world and has released a distrust in what the companies used to say – that they need billions of dollars to train their models and keep them working. As R1 was trained under serious constraints and with very little machinery (actually, they even used Huawei’s GPUs), what was thought to be true now is uncertain at best.
Since all of this was revealed, it is obvious that the market faced a big disruption and will not go back to what it was. So big was this impact that OpenAI has already announced a new and more cost-effective reasoning model, named o3-mini, which is designed to compete with R1. Another Chinese giant, Alibaba, has released a new model as well, named Qwen2.5-Max, which also aims to reach this renovated competition. It is clear, then, that the race for the best model has been renewed and is just getting started once again – the market has gained a new breath of life.
Still, there’s one new big giant whose future is yet to be understood – Nvidia. Its actions dropped by 15% after the release of R1, and we don’t know yet the future of the presence of its extra-expensive GPUs and TPUs in the market. We now know that their dominance over the industry isn’t as solid and absolute as previously thought, and also know that good LLMs can be developed outside of their domain. So, as Nvidia exploded by selling pickaxes to current gold-diggers, now we must discover how the market will behave towards it.
Conclusion
Given all of that, the greater benefit comes to the users and developers who can get the best experience and top-tier technologies on more cost-effective solutions. As cited previously, AI APIs were quickly lowering the profit margins of SaaS companies by even a third, due to how much it was used and how crucial it became for many products. With this, margins can remain as they used to be, while also growing in quality and becoming faster and faster. Also, as new AIs become more efficient and start to consume less energy, the environment will suffer less from carbon emissions and water usage related to this technology.
And, in case your application does not make use of DeepSeek-R1 yet, you can contact us at Chudovo and see that our consultancy services help your app use brand-new technologies. It’s the best way to power up your company with the capabilities of AI and discover how it can suit your needs, whichever they might be, making your processes faster and more solid. Join this brand-new wave and let us help your application reach its best equipped with the power of artificial intelligence!