Why Vibe-Coded Apps Break in Production Best Practices for Cleanup
If we have to describe what “vibe coding” means in just a few words, we can say that it consists of describing what you want in plain, natural language and letting an AI generate the code based on such a description. So, in contrast with traditional development, you don’t need to write any piece of code. In theory, developers can generate substantial amounts of code without writing every line manually. The underlying language still matters (reading, reviewing, and steering AI output requires enough understanding to catch what the model gets wrong), but the implementation burden shifts significantly.
Several tools, such as Cursor, GitHub Copilot, and Claude, have made this practical for a wide range of developers. A working prototype in a few hours is not unusual. The boilerplate grind, for the most part, is gone. While that speed is real, so is the cost that shows up later.
Applications put together this way often clear their first demo without issue. The happy path works, and a handful of users causes no trouble.
But then you start adding real traffic, changing the initial requirements, or bringing in more engineers to add new features, and things start to crack. At that point is where you realize all the things that the vibe-coded application ignored at the development. Generating code is the easy part. The harder job is turning that output into something a team can operate, extend, and trust.
This article looks at what breaks technically and what the vibe coding cleanup services actually involve. While this does not pretend to be exhaustive, here we’ll go through the most common pitfalls that engineering teams (and sometimes non-technical people) incurred during vibe code development.
The Technical Reality
Modern coding agents have real mechanisms for maintaining context across a codebase. Among others, these are the most popular tools that serve that purpose:
- Cursor Rules.
- AGENTS.md files.
- Semantic search
- Repository indexing.
- MCP-based integrations.
All of those help. The gap appears when teams skip that setup.
A project where nobody configured context management deliberately will behave as if each session starts from scratch, not because the tools cannot do better, but because nobody asked them to. Without sufficient context, the model will generate what appears reasonable for the immediate task while potentially missing architectural decisions, business rules, or implementation details that exist elsewhere in the codebase.
You can imagine what comes as a result: a piece of code that looks correct on a file-by-file basis but does not hold together as a system.
As said before, context management from the developer might help to mitigate this risk. But that’s not the only one to be aware of. Below are some of the most relevant concerns Chudovo’s team collected after working directly inside a vibe-coding workflow:
Inconsistent architecture
One of the most common approaches when doing vibe coding is to generate different parts of an application in separate sessions, with slightly different prompts. While this looks good for the vibe coder, it creates drift across the codebase: one module fetches data directly from the database; another uses a service layer; a third calls a REST endpoint that bypasses both. Each choice might be defensible on its own. Three patterns coexisting in the same codebase make every future change harder than it should be.
The cleanup starts with mapping what actually exists, not what was intended. Document the data flows, pick one approach as the standard, migrate the outliers.
Duplicated business logic
Another common pitfall is when business rules end up in multiple places: a controller, a background job, a frontend validation function, a database trigger. Each copy is correct at the time it is written. They diverge over time, silently.
While working on the stabilization of a vibe-coded project, Chudovo’s engineers discovered that the discount logic in the checkout service returned a different number than the order summary page. Tracking down why it cost two engineers most of an afternoon. And that was not optional: before you can consolidate, you have to understand what each version was actually supposed to do.
Hidden technical debt
AI-generated code takes the path of least resistance. That path often has problems that only appear under load. N+1 queries are the most common example. This exact pattern was identified during a review of an AI-generated e-commerce backend:
orders = Order.objects.all()
for order in orders:
# in the real code, this line was a separate DB query per iteration
print(order.customer.name) For ten orders, there’s no visible problem. When it scales to ten thousand, the database is overwhelmed. A single select_related call fixes it, but only if someone catches it first.
Related patterns that slip through: exception handling that swallows errors without logging them, connection pools sized for a laptop, verbose log output that nobody reads.
Missing test coverage
Tests appear in AI-generated code when you explicitly ask for them. When you do not ask, they do not appear. The tests that do get written tend to be surface-level: does the function return a value, does it throw an exception? Edge cases and failure modes get skipped. Cross-component behavior rarely gets tested at all.
The result is a test suite that gives false confidence. Green CI is not the same as a correct application.
Security risks
Security issues in AI-generated code tend to be the obvious kind: input validation that only runs on the client, SQL queries built with string formatting, API keys hardcoded in source. None of this is subtle. It is just easy to skip when the goal is a working prototype.
The following SQL injection risk is often present as part of AI-generated code:
query = f"SELECT * FROM users WHERE email = '{email}'"While a safer version would be:
cursor.execute(
"SELECT * FROM users WHERE email = %s",
(email,)
)The following table describes the most common risks from AI-generated code:
| Risk | Common AI-generated pattern | Correct approach |
| SQL injection | String-formatted queries with raw input | Parameterized queries |
| Secrets exposure | Hardcoded API keys or .env files committed to git | Secrets stored and rotated through a dedicated secret manager |
| Missing auth | Endpoints with no middleware guard | Auth middleware on all protected routes |
| Input validation | Client-side checks only | Server-side validation, not dependent on the client |
Scalability bottlenecks
N+1 queries are the most visible problem, but they’re not the only ones:
- Synchronous operations that should run in the background to avoid blocking request threads,
- Missing indexes for columns that are queried constantly, and
- Request handlers that accumulate logic and slow down under concurrency
All of those are examples of anti-patterns that you might find in AI-generated code. At demo scale, none of this shows. At the production scale, it compounds.
CI/CD and deployment gaps
Deployment configuration is often the last thing generated and the first to cause problems. Staging and production configs differ in ways that were never tracked. Health checks return 200 regardless of whether the application can actually reach its database. A container that runs cleanly on a laptop can fail silently in a Kubernetes cluster if the readiness probe checks a route with no real dependency validation behind it.
What the Cleanup Actually Looks Like
Chudovo’s team usually follows a practical path as part of the development process:
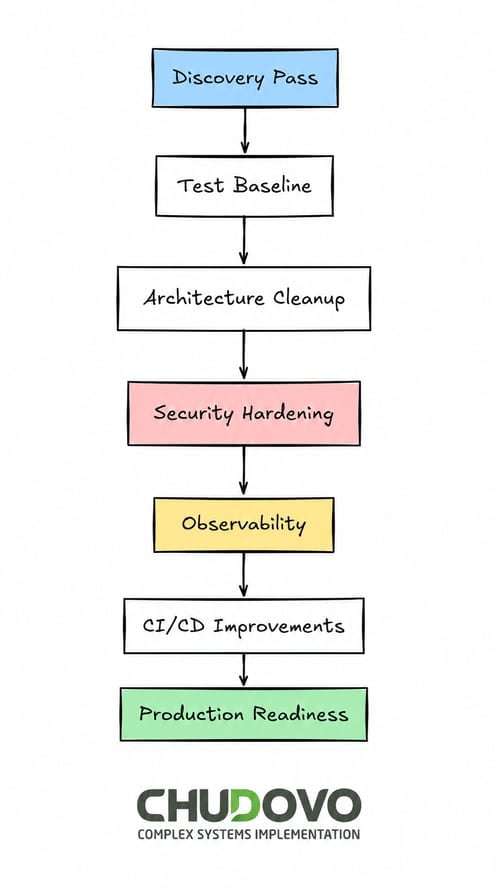
The discovery pass is the initial step that should be done before changing anything. Its main purpose is to understand what is there. In order to do that, developers have to read the code, trace the data flows, and run the app against data that resembles real usage. Of course, what’s key here is to write down every finding in order to identify the most serious problems and prioritize. After the initial investigation is done and before you start refactoring any piece of code, it’s always recommended to establish a test baseline. Even a thin layer that covers the core user flow could help, as it will give you a base to catch potential regressions. It also surfaces parts of the code that resist testing and highlights structural issues.
What comes next is to triage and clean up the architecture. To do this, you have to pick one data-access pattern and consolidate duplicated business logic. Do it incrementally, starting with the most current friction points or the areas most touched by the team. Once the architecture is ready, you have to tackle security. Some of the classic fixes involve parameterizing queries, moving secrets to a secret manager, and adding auth middleware. Running a dependency audit is also mandatory to identify and fix potential issues in third-party packages. This has to be done before the application handles real user data. Unpatched dependencies are a common entry point for attacks, and a dependency audit is the fastest way to find them.
The two final steps are about observability and the CI/CD pipeline. Regarding the first one, you need to establish structured logging with error rate metrics and latency alerts. This is crucial because if you can’t see what your application is doing, it will be hard to know what’s going on. On the pipeline side, you have to put a real CI in place, with real tests. Have explicit staging and production config and health checks that verify actual dependencies, not just process liveness.
While the proposed approach does not pretend to be exhaustive, the order matters: first analyze, then implement and fix. Finally, focus on CD and monitoring.
Timelines and Finish Lines
The entire process of stabilizing a vibe-coded codebase rarely takes less than a few weeks for a small prototype. In large projects, a realistic estimate is one to three months of part-time engineering attention running alongside normal feature work.
The most common mistake several development teams face is to treat it as a sprint: scoping a two-week cleanup, declaring it done, and moving on. What usually happens is that each layer of fixes reveals the next one. Several security issues surface during the architecture pass; some missing indexes show up only after the test baseline exposes slow queries. As things keep adding up, the initial plan breaks.
A good approach is to consider this an iterative process from the beginning. This will give your team a sense of gradual (but real) progress, together with the flexibility to accommodate the new tasks as they’re discovered during the process.
Knowing when to stop is a separate problem. Most teams consider that “Production-ready” means the codebase is fully clean. By having such a target, teams continue iterating over and over again while rescheduling the release indefinitely. From Chudovo’s team experience, a codebase that meets the following four criteria is ready, even if the architecture is still inconsistent in places and the test coverage is nowhere near complete:
- The failure modes are understood by the team.
- The critical paths are tested.
- The obvious security gaps are closed.
- The team can make changes without fear of breaking something else.
Remember: chasing perfection here is a trap. The goal is a system the team can operate and evolve with reasonable confidence, not one that would pass a senior engineer’s code review with flying colors. That bar can be raised incrementally, after the immediate risk is under control.
A Note on Pace
While most of the development teams are aware of the topics mentioned above, their temptation is usually to fix everything at once. They end up going in circles, never reaching production because the cleanup scope keeps expanding.
As it was explained in the sections above, a comprehensive refactor of an AI-generated codebase is a large, risky project with many opportunities to introduce new problems. Teams that stabilize these codebases effectively tend to move incrementally. Fix the blocker today. Add tests as you go. Shift the architecture toward coherence over weeks. The progress feels slower, but the application keeps working throughout.
AI can dramatically speed up software delivery. Production reliability is still a function of architecture, testing, observability, and operational discipline. The teams that get this right are not the ones that generate the most code. They are the ones who see such code as a starting point, not a finished product.