AI as an Operational Layer: Embedding Intelligence into Enterprise Systems
When enterprise software teams started to integrate AI into their systems, the approach was to integrate its capabilities feature by feature: a chatbot here, a recommendation widget there. As the models continue to evolve, the paradigms do the same.
The recent trend has shifted from doing single AI implementations to having the AI as an operational layer. Under this approach, the model spans systems capabilities rather than being a piece of just one of them.
As organizations continue to operationalize AI, the challenge shifts from isolated experimentation to maintaining consistency across systems, teams, and use cases. The real leverage comes from treating AI as shared infrastructure, where decisions about orchestration, governance, and data handling are made deliberately early, rather than being patched later under production pressure or after scaling issues surface.
In the sections below, we’ll present Chudovo’s point of view regarding such a topic. We’ll discuss how orchestration fits in, what governance has to cover, where data boundaries are crucial, and what the cost picture looks like at scale.
What an AI Orchestration Layer Is
In a simplified version, an operational layer is a piece of your system that sits in the middle of two other pieces. Generally, on one side, you have a core system or records; on the opposite side, the interfaces or processes that consume them.
The main purpose of the operational layer is to orchestrate the communication between the two sides. It takes care of coordination, translation, enforcement, and routing.
If we plan to embed an AI in this layer, our main purpose is more than just using it to answer questions. We expect AI to provide valuable insights. We want it to get involved in real workflows like the following:
- A model that triages incoming support requests and updates a CRM record
- An AI pipeline that validates contract language before a document routes to legal review
- A classification system that tags transactions in near-real time for downstream compliance checks.
In all cases, the model will receive inputs from multiple systems, apply logic, and return outputs that affect what happens next. That’s the aggregate value the AI could provide.
While a feature-level AI component demands accuracy, an operational AI component needs that, plus auditability, recoverability, observability, and cost control. The question here won’t be “did the model get it right?”. What actually matters is if we can prove what it did, and reverse the course if it was wrong.
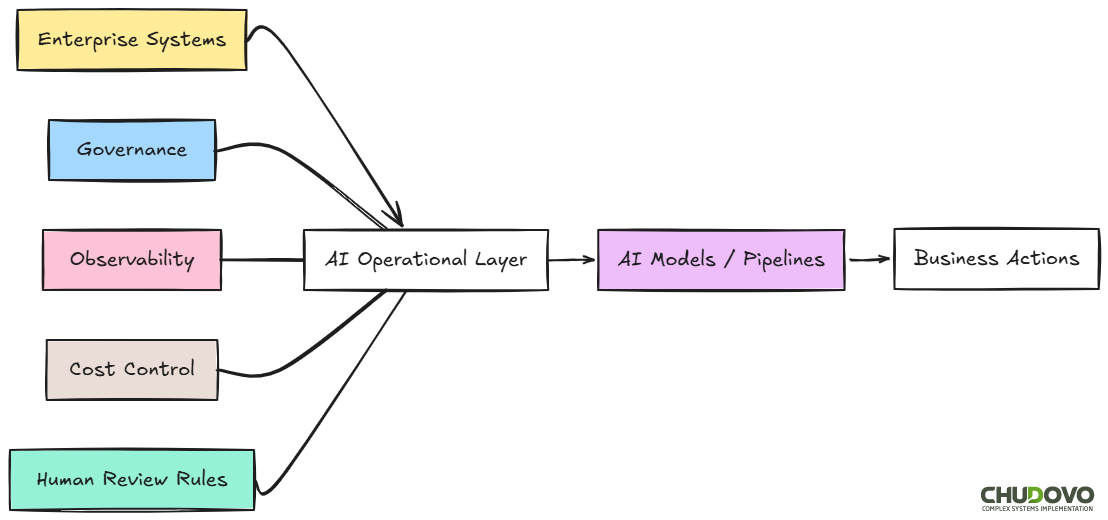
The Orchestration Problem
At scale, embedding AI into enterprise systems requires an AI operational layer. Companies that ignore this may end up with AI calls scattered across codebases, inconsistent retry logic, no central visibility into failures, and no practical way to enforce policy changes without touching every service individually.
A well-designed model orchestration layer may take care of:
- Choose which model or pipeline handles which request type (Routing)
- Decide what happens when a model call fails or returns a low-confidence result (Retry and fallback logic)
- Versioning and deployment of prompts across environments (Prompt management)
- Prevention of cost spikes or degraded throughput under load (Rate limiting and throttling)
- Provide visibility into what happened at each step of a pipeline (Logging and tracing)
The example below is simplified but representative. Chudovo’s team often follows this pattern on any enterprise engagement where multiple AI services are needed to share routing logic without duplicating it across services.
// Simplified orchestration dispatcher
const pipelines = {
contract_review: contractReviewPipeline,
support_triage: supportTriagePipeline,
transaction_flag: transactionClassificationPipeline,
};
async function routeRequest(requestType, payload) {
const handler = pipelines[requestType];
if (!handler) {
throw new Error(`No handler registered for: ${requestType}`);
}
try {
const result = await handler(payload);
logEvent(requestType, payload, result, { status: "success" });
return result;
} catch (err) {
logEvent(requestType, payload, {}, { status: "error", error: err.message });
throw err;
}
}This pattern centralizes AI observability and is a good example of what a well-structured AI orchestration layer looks like in practice.
AI Governance Framework
Most companies talk about responsible AI governance, but few are actually doing it. A single AI component is tractable. Ten of them, across different teams with different model providers, is a different problem. As the system grows, complexity scales quickly.
A solid governance for enterprise AI systems begins by clear policies about model lineage and access control. This means which model version produced a given output, and when; also, which systems or users can invoke which AI capabilities.
But this is not enough. Clear Rules about what AI can and cannot do in specific contexts are also mandatory. For instance, a model flagging transactions cannot automatically freeze accounts without human review.
For audit purposes, a tamper-resistant record of what the model returned is required. It has to be complemented with a monitoring system for degradation in model output quality over time.
Defining a governance contract per pipeline is one way to go. It does not have to be elaborate, but useful. A lightweight spec that covers model version, audit log location, retry policy, escalation path, and the conditions under which a human must be looped in is more than enough.
const contractReviewGovernance = {
modelVersion: "claude-sonnet-4-20250514",
auditLog: {
destination: "s3://audit-logs/contract-review",
retentionDays: 365,
},
retryPolicy: {
maxAttempts: 3,
backoffMs: 500,
},
escalation: {
triggerOnConfidenceBelow: 0.75,
notifyChannel: "legal-review-queue",
},
requiresHumanReview: (result) => result.flagCount > 0,
};The example above shows a small but concrete piece of a broader AI governance framework. The requiresHumanReview condition is worth paying attention to. It’s the line that separates automated AI decisions from ones that need a person in the loop. Getting that threshold wrong, in either direction, is one of the more common mistakes teams make when moving from a single pipeline to a production system.
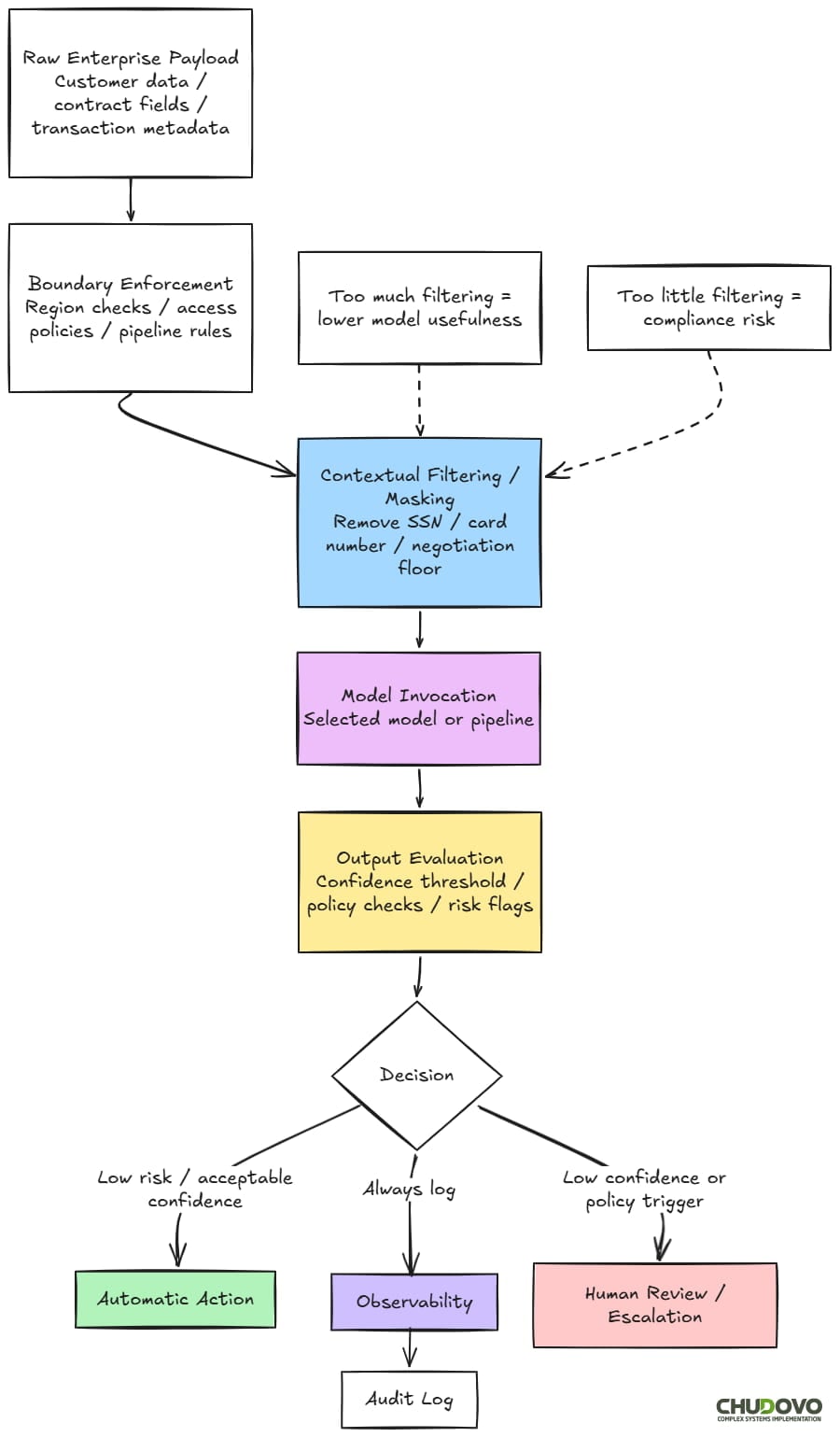
Data Boundaries in AI Systems
If you’re looking for a place where theory meets enterprise reality, that’s data boundaries.
AI models need access to data to be useful. For large language models used in retrieval-augmented pipelines, this is even more relevant. On the other hand, most large organizations have data that cannot cross certain lines: by regulation, by contract, by internal policy, or by customer agreement.
One can certainly sense the tension. But it will not be solved by itself, sadly. You need to address it with concrete actions. In our experience, organizations that treat data boundaries as an afterthought in enterprise data architecture end up retrofitting them later. That’s significantly more expensive.
One of the most common (and trickiest) techniques that you can use is Contextual Filtering. Take a look on the following example:
function applyContextualFilter(payload, pipelineType) {
const sensitiveFields = {
support_triage: ["creditCardNumber", "ssn", "bankAccountId"],
contract_review: ["internalCostBasis", "negotiationFloor"],
};
const fieldsToRemove = sensitiveFields[pipelineType] ?? [];
// In practice, fields may be removed or masked depending on schema requirements
return Object.fromEntries(
Object.entries(payload).filter(([key]) => !fieldsToRemove.includes(key))
);
}
// Usage before routing
const filteredPayload = applyContextualFilter(rawPayload, "support_triage")This technique is used to strip or mask sensitive fields before data reaches the model. It’s very useful, for instance, to obfuscate customer data in support pipelines. But here is the thing: Strip too much, and the model loses the context it needs to return a useful result. Following the example above, the tradeoff is pretty clear: a support triage model that can’t see account type will misclassify routing for enterprise vs. SMB customers at a rate that’s noticeable in production.
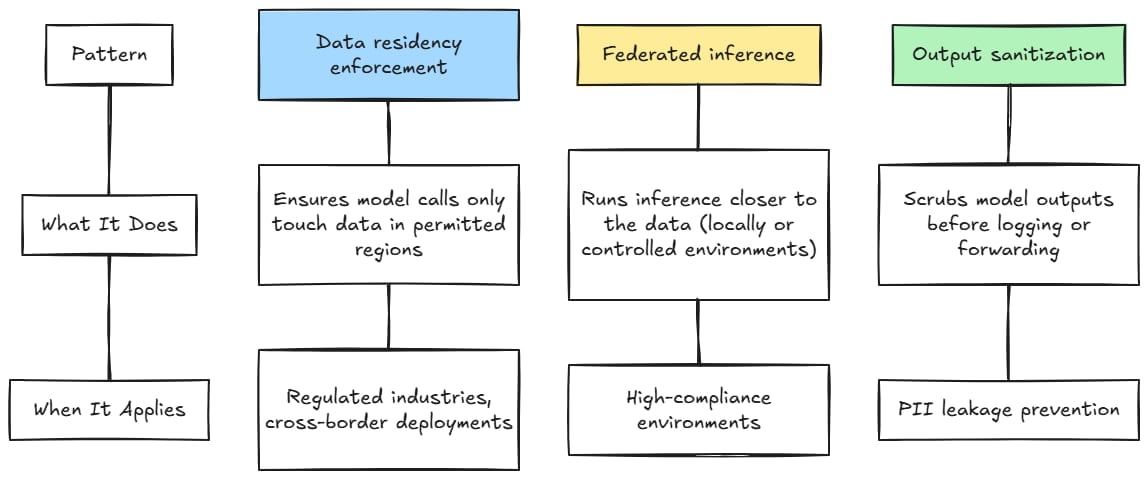
There are other useful patterns for AI compliance and risk management.
AI Infrastructure Management
Running a single AI-powered feature is cheap enough, so usually you do not have to consider a separate budget for it. When you want to build and run an AI as an operational system, that’s a different story.
There are 3 main drivers for the cost of enterprise AI deployment:
- Inference
- Latency
- Observability
Inference cost is the most evident one. The token pricing policies followed by major LLM providers, when combined with high-volume operational AI pipelines, can accumulate costs quickly.
Consider the following:
- A pipeline that handles 100,000 requests per day, at an applicable pricing of $0.01 per 1,000 tokens.
- An average token’s consumption of 500 tokens per call
If you do the maths, this means roughly $500/day only for this given pipeline. Multiply that across several pipelines, and you’re looking at meaningful infrastructure spend.
On the other hand, any operational AI systems often need low-latency guarantees, so, in practice, this means you might need to have multiple instances of your model running at the same time. Another strategy is to use a cheap (but less capable) model for triage and simple tasks and let it escalate to a more complex (thus, more expensive) one for specific cases that require such attention.
While both of those approaches may work. They could also increase the average cost per request.
Finally, a well-designed observability system (centralized logging, trace storage, model monitoring, and governance tooling) carries infrastructure costs.
All the factors above are consistently underestimated in early planning. In Chudovo’s experience, building a scalable AI infrastructure requires treating cost as an ongoing operational concern, not a one-time estimate. Cost models need to be considered per pipeline, not per deployment. It must consider token consumption, fallback rates, and escalation frequency. And it has to be complemented with budget alerts to prevent spikes.
Enterprise AI Integration Without Full System Rebuild
If you’re starting from scratch, integrating an AI system at an operational level is straightforward. You include it as a part of the whole development process and make sure your stack is compatible with such an integration.
The real challenge is to embed this layer into a system that is already up and running.
Probably you have one question in mind: Do I need to rearchitect everything to accomplish this?. The honest answer is “it depends on what you have.”
If your existing system is a tightly coupled monolithic system, there will be hard work to do. At the end, you’re trying to make the AI layer work around integration points that weren’t designed for it. This can be fixed, for sure, but often you’ll need to build adapter layers, which is maintenance work that compounds over time.
Let’s say you’ve already built your entire system on event-driven architectures, message queues, or service meshes. In that case, accommodating them to AI orchestration does not require major surgery. What you have to do is to include your AI components as consumers or producers on existing event buses. The orchestration layer sits alongside what’s already there.
In both cases, an incremental enterprise AI integration is dramatically more recoverable than a big-bang approach. The basic workflow would be to start with a bounded, non-critical pipeline; instrument it properly. Then, understand the cost and failure behavior before expanding.
Building a Real Enterprise AI Architecture
To embed AI into your enterprise software, you need more than just connecting the model to your pipeline. Observability, governance, data architecture, and cost management are problems that do not emerge gradually. They show up early, often just before the first production deployment takes place.
What you decide in that first pipeline sets the pattern for what follows. Orchestration design, governance contracts, and data boundary policy shape everything that comes after. A wrong choice at that point, and you’ll pay the price later. The real issue is that, most of the time, the team that owns the first pipeline rarely owns the second one.
As AI expands across the organization, different teams inherit decisions they didn’t make. Here’s when early work on orchestration contracts and governance specs matters. Any team can pick up, audit, and extend a well-documented pipeline. A poor one will be a black box that nobody wants to touch. As you can see, the real issue is usually not the model. It’s the AI infrastructure around it.
And that infrastructure, once it exists, becomes the foundation every future AI initiative in the organization will build on. Getting it right the first time is not about perfectionism. It’s about not inheriting a system that fights you every time you try to extend it.
Companies that succeed in enterprise AI integration work through those factors deliberately. They tend to scale more cleanly than those that treat infrastructure as something to figure out later.