From Fragmented Systems to Unified Architecture: Building Enterprise Integration Layers
Most large companies start with a CRM. As business evolves, they add an ERP, then a data warehouse, a few internal tools, maybe a third-party analytics platform as well. Each addition made sense at the time.
Five years later, nobody can tell you with confidence what happens to a customer record when it’s updated in the CRM. That’s what happens without a real plan for enterprise integration architecture.
Such a plan is not about a full replacement of those tools. Its main purpose is to build an integration layer that connects all of these systems, moving away from a rigid architecture of point-to-point API dependencies.
In the sections below, we’ll discuss how Chudovo’s team approaches this plan using:
- Event buses
- Middleware
- Data consistency strategies
- Security
We’ll focus on the pros and cons of each of them. These patterns apply whether you’re on Kafka, RabbitMQ, EventBridge, or something bespoke. The vendor choice matters less than getting the shape of the layer right.
Event Bus Architecture
Here’s what’s known as a Point-to-Point integration:
- Service A calls Service B’s API.
- B pushes data to C via a webhook.
- C writes to a shared database that D reads from.
In such an architecture, every service depends on at least one other service.
It holds together for a while. After you add the third or fourth service, you notice that each new integration will double the number of connections you have to maintain.
Now, let’s consider an alternative approach. Instead of Service A calling Service B directly, A publishes some information to a central bus. Any service that cares about it takes such information and processes it on its own terms.
This is what Event Bus Architecture is about. And the “information” is what we know as an event.
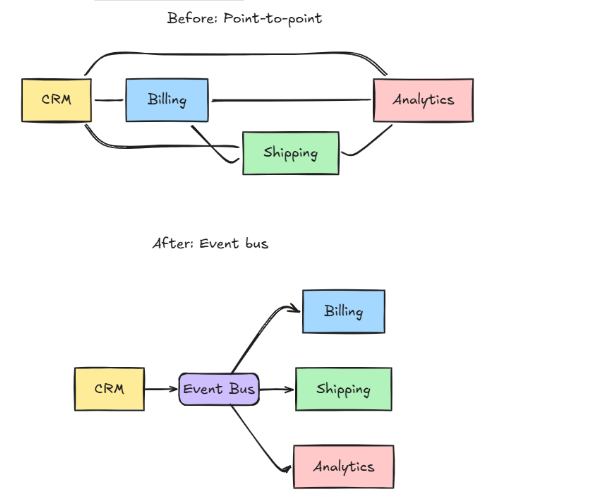 Take a CRM that fires an event every time a billing address changes:
Take a CRM that fires an event every time a billing address changes:
{
"event": "customer.address_updated",
"customerId": "cust_8812",
"timestamp": "2024-11-14T09:22:00Z",
"payload": {
"addressLine1": "742 Evergreen Terrace",
"city": "Springfield",
"country": "US"
}
}This event is published once. Each system interested in such a change subscribes to customer.address_updated.
After the event is received, each consumer handles it in their own context and schedule, with their own retry and error logic. The CRM has no knowledge of any of them.
As you have seen, the main benefit is system independence. The producer only takes care of publishing the event. Any system interested in such an event subscribes and retains the implementation logic. When a new consumer is subscribed, the producer remains untouched. If such a consumer falls over during processing, the producer keeps running.
There is one thing to consider, though. An event could be processed by the consumer 200ms after it’s published, or 30 seconds later if it’s under load. For a service that needs a synchronous, strongly consistent response, a direct call might be the way to go.
Middleware Strategy: What Goes in the Integration Layer
A middleware is often seen as “the thing that passes messages around.” The truth, however, is that this architecture covers a range of responsibilities.
In all enterprise systems, there are several cross-cutting concerns that should not be implemented separately by individual services. Instead, one of the main responsibilities of a well-designed middleware architecture is to serve as the enforcement point for them.
A middleware layer usually performs the following tasks:
- Route and transform messages. It converts an event from the schema one system produces into the schema another system expects (It may use a Schema Registry to ensure compatibility and prevent downstream breaks).
- Translate protocols, so systems that ‘speak’ different languages can talk to each other.
- Rate limits and backpressure. The middleware implements appropriate measures to protect downstream services from being overwhelmed by event bursts.
- Dead-letters. It captures events that couldn’t be processed and surfaces them for investigation.
- Observability. The middleware takes care of centralized logging, tracing, and alerting across all message flows.
If there is something that does not belong to the middleware, that’s any business logic. What a CustomerUpdated event means for billing should be out of the middleware’s scope. It transforms and routes; it doesn’t interpret.
Enterprise Messaging Systems: ESB vs. Lightweight Brokers
For years, the dominant pattern was the Enterprise Service Bus (ESB). This means a centralized platform that handles routing, transformation, orchestration, and more.
While this approach serves well to its main purpose, they tend to become an organizational bottleneck. Every new integration requires a change to the central bus configuration, which often means a separate team and a change approval process.
Based on the microservices communication patterns, a different approach came into play: lightweight message brokers (Kafka, RabbitMQ, AWS EventBridge, Google Pub/Sub) combined with thin, purpose-built consumers. Each service owns its own subscription logic. The broker handles delivery, durability, and ordering guarantees.
Below is a quick comparison of both approaches:
| Dimension | Enterprise Service Bus | Lightweight Message Broker |
| Centralization | High | Low |
| Operational overhead | Higher often requires a dedicated team | Lower per-team, higher aggregate coordination |
| Transformation | Built-in | DIY or separate transform service |
| Scaling | Vertical, often limited | Horizontal, designed for high throughput |
| Best fit | Regulated industries, legacy integration | Cloud-native, microservices-heavy orgs |
With a message broker, the integration concern goes back toward the teams that own the services. This can be either an improvement or a coordination problem, depending on your organization.
Data Consistency in Distributed Systems
You can’t have strong consistency across independently-deployed services without trading away some availability or partition tolerance. This is well-known as the CAP theorem, and no amount of clever tooling gets around it.
What you can do is design for specific consistency guarantees where they matter, and accept eventual consistency where it doesn’t.
Outbox Pattern
Let’s say you update a database record and want to publish an event. If the event publish fails after the DB write, you have a silent inconsistency.
One of the most useful data synchronization strategies for event-driven architectures that aims to solve this issue is the transactional outbox.
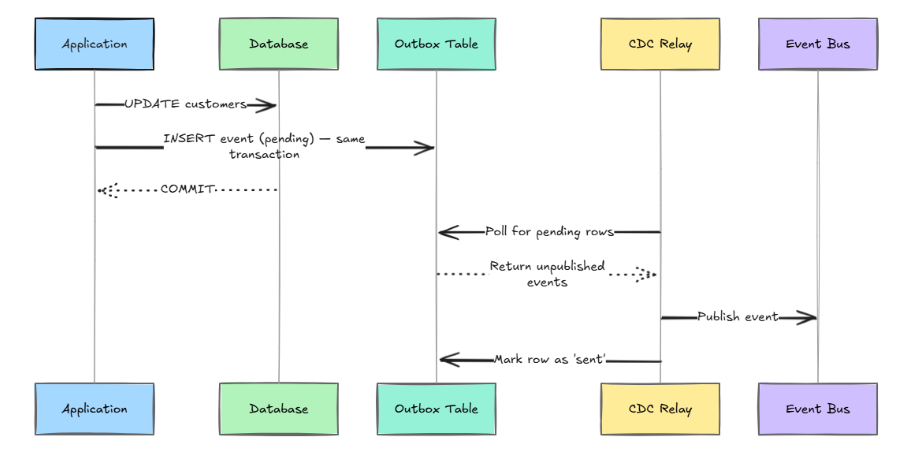
By following the approach above, your event is guaranteed to be published if and only if the database write succeeds:
-- Application writes both in one transaction
BEGIN;
UPDATE customers SET address = $1 WHERE id = $2;
INSERT INTO outbox (event_type, payload, status)
VALUES ('customer.address_updated', $3, 'pending');
COMMIT;
-- CDC relay picks up pending outbox rows and publishes them
-- Marks rows 'sent' after successful publishThere is a tradeoff, though. You need a reliable CDC relay process, and you’re adding a second table to every write path that needs event publishing. For most teams, that cost is worth the consistency guarantee.
Idempotency
Most enterprise messaging systems guarantee at least once delivery, not exactly once. That means consumers need to handle duplicate events gracefully. The standard approach is to include an idempotency key in every event and track which keys have already been processed. The second process is a no-op.
For example:
-- Idempotency guard in the consumer handler
CREATE TABLE processed_events (
event_id TEXT PRIMARY KEY,
processed_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
BEGIN;
INSERT INTO processed_events (event_id)
VALUES ($1)
ON CONFLICT (event_id) DO NOTHING;
-- 0 rows inserted = duplicate event, skip in application layer
COMMIT;There are real edge cases to consider, though. For example, when the processing involves external side effects like sending an email or charging a card, you generally need to push the idempotency guarantee into the downstream system itself, not just your event handler.
Security Model for Enterprise System Integration
Secure enterprise system integration is more challenging than securing individual services. This is partly because the attack surface is wider and partly because integration layers often receive less security scrutiny than the systems they connect.
In our experience, authorization at the topic level is the area that is skipped most of the time. Teams lock down who can connect to the broker, but leave topic subscriptions wide open. This is known as the ACL gap.
If a service can read from a topic, it can see every event on it. This includes the ones that carry PII or financial data. Ignoring this may lead to data leaks that could introduce high vulnerability issues.
Other pieces that also matter in terms of security are:
- Short-lived service credentials
- TLS in transit
- Field-level encryption for sensitive payloads
- Audit logging
However, ACL Gap is where you’re most likely to find real exposure.
Authentication and Authorization at the Bus Level
The most common approach to handle authentication is to integrate with your identity and access management architecture to issue service-specific tokens (e.g., OAuth 2.0 client credentials flow, or workload identity in cloud environments). Any service that publishes or subscribes to your event bus should authenticate with the bus using short-lived credentials. The use of long-lived API keys embedded in config files should be avoided.
Here’s the rule of thumb: authorization needs to be explicit. Service A can publish to topics it owns, and subscribe to topics it has been explicitly granted access to. The default posture should be deny-all, not allow-all.
An over-permissive topic subscription is a common way for a noisy or misconfigured service to receive data it shouldn’t have, so the rule above matters more than it might seem.
Encryption and Data Classification
Events in flight should be encrypted in transit (TLS 1.2+ minimum, prefer TLS 1.3). For sensitive payloads, consider field-level encryption in the event payload itself. In this case, individual fields are still protected even in the case someone gains unauthorized access to the message broker’s storage.
Examples of those are:
- Anything containing PII
- Financial data
- Health records
It’s worth classifying your event types early. A product catalog update is low sensitivity; a customer payment update is high. Applying the same security controls uniformly is expensive and often leads to teams cutting corners. Apply controls proportionate to the classification.
Audit Logging
Your integration layer is a natural enforcement point for audit logging, because it has visibility into data flowing between all your systems.
Instead of just logging errors, normal operations should also be included. Examples of valid logs are:
- Who published what, when, and to which topics.
- Consumer acknowledgments
Rather than just a compliance requirement, this is the most reliable way to debug data inconsistency issues after the fact.
Common Failure Modes in Enterprise Integration Layers
Predictable failure patterns may exist even in well-designed integration platforms. Some of them often don’t show up as outright errors, but as subtle data drift or unexplained system behavior:
- Schema Drift: Whenever a producer renames a field or changes a type without coordination, consumers will silently start to parse incorrect data or fail with unhelpful errors. To prevent this, you should implement a schema registry that performs compatibility checks at publish time.
- Consumer lag: It happens when a slow consumer accumulates a bunch of backlog. This could lead to a real consistency problem. You should monitor consumer lag as a first-class metric, not an afterthought.
- Circular event loops: Take a service A that publishes an event that triggers Service B to update a record. Such an update triggers Service A to publish again. This may be infinite. To prevent this, it’s important to include some metadata, such as causation and correlation IDs. Consumers should not re-publish events that originate from their own actions.
- Outbox table bloat: If a CDC relay falls behind or fails, the outbox table grows indefinitely. You should monitor the outbox table size and relay health independently of the core application.
Putting It Together: An actual service integration layer
Designing a unified enterprise system architecture doesn’t require replacing your existing systems. It requires introducing a coherent layer between them. At minimum, that layer needs:
- A message broker with durable storage, configurable retention, and consumer group support.
- A schema registry that enforces event contracts between producers and their consumers.
- A middleware layer responsible for routing, transformation, and protocol bridging (no business logic).
- A centralized view of pipeline health, monitoring event bottlenecks, failures, and total processing time.
- A clear security posture with mutual authentication, topic-level authorization, and audit logging.
Where engineers spend the most time debugging data discrepancies or maintaining fragile API connections is where you should start. Build the integration layer there first, get it working and observable, then expand outward.
The goal here isn’t to make your systems look simple from the outside. It’s to put the complexity somewhere with boundaries: where it can be tested in isolation, monitored with actual metrics, and understood without needing context from six different teams. That’s a real enterprise integration architecture you can actually build.