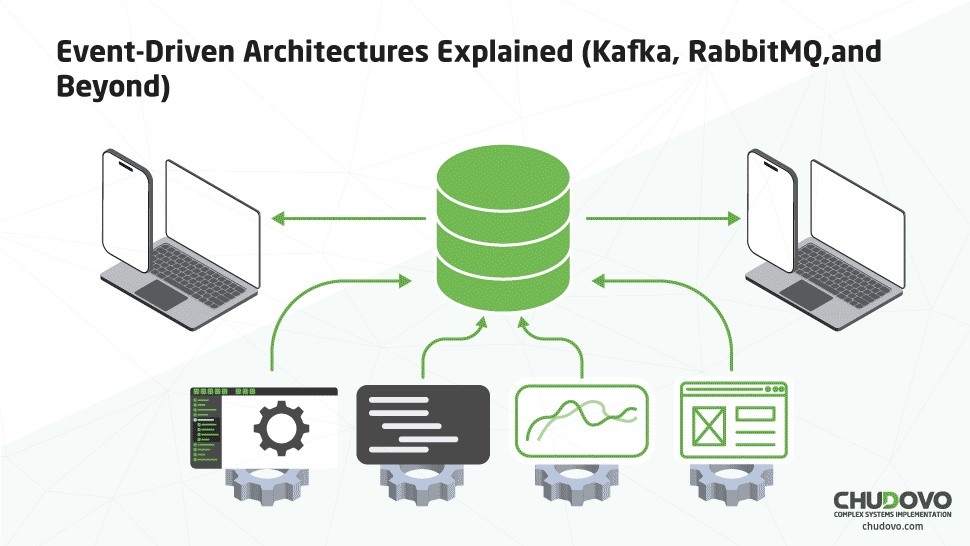
Event-Driven Architectures Explained (Kafka, RabbitMQ, and Beyond)
In modern software development, microservices patterns are typically the default solution for building scalable, performant, and easily maintainable software for web platforms and systems. It works very well on both the front and back ends, and nowadays it is also easy to maintain and deploy these various microsystems. In this context, the event-driven architecture is an important backbone to the communication between different services. In this article, we will explain event-driven systems and their fundamental importance in creating up-to-date and profitable web solutions, enabling your customers to have the best experience using your products.
How Event-Driven Architecture Works
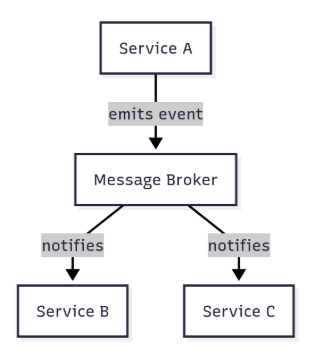
Event-driven architecture is a pattern that utilizes messaging services to send information to a queue when an event occurs (hence the name). This queue will then process the different messages, and another service should be configured to listen to this queue; it will then receive the message and process it. The overall architecture consists of the implementation of three basic services, which are producers, consumers, and event brokers.
The services that send the events are called producers; the ones that process them are the consumers, and, lastly, there’s the intermediary service, which is called the event broker. It is the one responsible for implementing the queue to send information between the different services, and is usually an online service such as Kafka, RabbitMQ, AWS SQS, among others. It routes the messages, interprets where they should be sent, and then directs them to the correct destination, as the services very frequently can’t communicate with each other upfront. This scheme exemplifies the architecture:
Furthermore, there are two ways for applications to communicate: via message queues (the most common way) and pub/sub architectures. The former is more or less the default, and in it, each message goes to a single consumer, and it works as a queue of tasks that need to be processed one at a time. The pub/sub pattern, on the other hand, refers to publish/subscribe and means that the producer dispatches events about a topic, and the consumers are subscribed to it. All consumers, then, receive the event at the same time. It’s especially useful when several different services need to get events from a single source, more or less like when news is broadcast on the radio. And, at last, it all works through well-defined and structured contracts, which all consumers and producers must follow very strictly to avoid data loss, corruption, or misinterpretation, and also schemas, which are the models that events must follow.
Benefits of Event-Driven Architecture
There are several different advantages to building systems with the event-driven architecture pattern. Most of all, it allows for the creation of scalable and performative projects, modelled with modern and up-to-date stacks that will be maintainable and easily improvable. Development cycles are faster once you get the hang of using events and communication between services; every feature can be safely and easily tied to old systems, while not compromising them.
Furthermore, it allows for a next-level experience in real-time data processing. That’s crucial for, for instance, web chats and live dashboards, which require data to be constantly updated. With it, multiple consumers can receive events at the same time, and so different databases and microservices can be updated at the same time. It is also the ideal solution for user experience, allowing for a much more fluid usage of your application, leading to higher user satisfaction.
Given all of this, event-driven architecture is for sure a really good option, and sometimes unavoidable, for building scalable, flexible, and performant code for big products. So, if your business needs to process real-time data at scale, adopting this code structure will be the right choice for you and your team.
Challenges in Implementing Event-Driven Systems
Even though the event-driven architecture has many upsides, there are some challenges and downsides in implementing it for communication between different services. For instance, if you don’t properly plan and structure your event-driven patterns and contracts, your projects can very quickly become a huge mess; so, here is a small list of the problems that can hit you and how to avoid them.
Complexity when trying to track events
As events very usually “travel” between different services, and sometimes between many of them, it can get seriously hard to understand where something comes from and where it is going. It works somewhat like “magic”, since during execution, you have no idea what the origin and destination of events are, and it is sent and received completely out of your control. To solve this, you must use logging techniques, both logging to your console for debugging and saving it into a log table in your database. One of the most important details of it is to learn how to create trace IDs, so that each event may have a specific UUID. When searching for them, you can receive precious information to both understand what’s happening and understand bugs and problems with your apps. Here’s a quick tip on how to implement it with NodeJS and using RabbitMQ as an event broker:
// install dependencies first:
// npm install amqplib uuid
import amqp from 'amqplib';
import { v4 as uuidv4 } from 'uuid';
function log(service, message, traceId) {
console.log(`[${new Date().toISOString()}] [${service}] [trace:${traceId}] ${message}`);
}
// Producer – sends event
async function producer() {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queue = 'orders';
await channel.assertQueue(queue, { durable: true });
const traceId = uuidv4();
const event = {
type: 'OrderCreated',
data: { orderId: 123, total: 49.9 },
traceId
};
channel.sendToQueue(queue, Buffer.from(JSON.stringify(event)));
log('Producer', `Event sent: ${event.type}`, traceId);
await channel.close();
await connection.close();
}
// Consumer – receives the event and registers logs
async function consumer() {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queue = 'orders';
await channel.assertQueue(queue, { durable: true });
log('Consumer', 'Waiting for messages...', '-');
channel.consume(queue, (msg) => {
if (msg !== null) {
const event = JSON.parse(msg.content.toString());
log('Consumer', `Event received: ${event.type}`, event.traceId);
log('InventoryService', `Updating inventory for order ${event.data.orderId}`, event.traceId);
channel.ack(msg);
}
});
}
// Start
consumer();
setTimeout(producer, 2000); // send event after two secondsDifficulty in keeping data consistency
Usually, types aren’t properly maintained and respected when information travels between several different systems. This problem with data types will surely lead to huge inconsistencies in your services, and that’s if it doesn’t make the system break entirely once it receives something unexpected, badly formatted, etc. To do so, you must plan very strictly for your software solutions, how to implement your events and how they will be typed in all your environments and services, so that the information within the event is trustworthy and not misleading.
Bigger learning curve
It is sometimes a bit confusing to start understanding event-driven architecture. It looks like the event is magically appearing in your service, or that it is sending an event to a blackhole, never to be seen again; it takes a little while to wrap your mind around it and really understand how it flows. Because of this, there’s a bigger learning curve to get used to using this architectural choice, and with this, the development and debugging processes will be slower in the beginning.
Necessity of event schema versioning
Lastly, it is very important to add versioning to your event schemas. As systems progress and become more advanced and complex, some events will need to change to be upgraded or refactored, and, if they aren’t properly versioned, bugs will occur. That’s because your systems won’t be synced to parse the same data structure and event types, and you might get glitches when trying to parse old events as well. This problem can also extend to other parts of your project: for instance, without proper versioning, audit logs can stop working, system reports won’t be reliable, and sometimes communications will be completely shut down.
How to Build Event-Driven Applications (Step-by-Step)
Though we have explained a bit about how event-driven applications work, it’s still very theoretical and abstract. Here’s a quick event-driven architecture tutorial, with an introduction to the practical aspect of implementing an event-driven application, utilizing RabbitMQ as an event broker and Node.js for the services.
- Define events and producers. That’s the planning stage, in which you must determine which functional blocks of your code must send events to the broker. If, for instance, you’re building a checkout system, then probably you want to inform other services when a payment is confirmed, or when a customer cancels a purchase.
- Choose a message broker (Kafka, RabbitMQ, etc). There are several available options. Some of them can be self-hosted, such as Apache Kafka or RabbitMQ, and others are sold by other providers, such as the Platform as a Service solution AWS SQS. As for these first two options, Kafka is typically the go-to choice when dealing with streaming or a high volume of data; RabbitMQ, on the other hand, is a simpler yet reliable solution for queuing.
- Set up consumers. These are the services that “listen” to the events and react to them. They can do tasks such as send emails, process inventory, and register logs, among others.
- Test and monitor the flow. To ensure it’s actually working, you must test your solution a few times, understand the process flow, and then look for blockages in the flow or any potential interruptions to communication between services.
To illustrate it practically, here’s an event-driven architecture example using NodeJS and RabbitMQ:
// Publisher
const amqp = require("amqplib");
async function publish() {
const conn = await amqp.connect("amqp://localhost");
const ch = await conn.createChannel();
const queue = "orders";
await ch.assertQueue(queue);
ch.sendToQueue(queue, Buffer.from("OrderCreated: #123"));
console.log("Event published!");
}
// Consumer
async function consume() {
const conn = await amqp.connect("amqp://localhost");
const ch = await conn.createChannel();
const queue = "orders";
await ch.assertQueue(queue);
ch.consume(queue, (msg) => {
console.log("Received:", msg.content.toString());
});
}As you can see, the code imports the library that adds support to RabbitMQ, creates a function named publish that connects to the event broker, creates a channel and names it “orders”, and finally sends an event to the queue. The function consume, on the other hand, performs a similar task in the initial steps, but ultimately establishes itself as a consumer for the queue, listening for updates, and then logs the message content to the console. That is, then, the very basic functioning of an event-driven system, and can already let you understand how easily you can scale and improve the loop that reads events to process whichever tasks you might need to build your app.
Conclusion
To sum everything up, the event-driven architecture explains how different systems may communicate with each other. To do so, they can either use simple queueing methods or the pub/sub pattern: the former is used to create first-in-first-out queues to process a series of information sequentially, and the latter is good for the broadcast of messages, when several different services need to know something. Given this, the architecture basically revolves around three entities: the producer, the event broker, and the consumer. They, respectively, produce the service and hand it to the broker, which, in its turn, routes the event to the destination, and the consumer receives it and processes the information received, doing something with it.
Now that you understand the event-driven architecture explained, you can already start implementing it into your software and take it to the next level, making it much more scalable and up-to-date with modern development practices. Remember always that choosing the right event broker is the secret to success: Apache Kafka, RabbitMQ, AWS SQS, and others. Each has its ups and downs, and differences emerge in the details and daily usage. So, it’s now your turn to build something great and performant with this very useful architecture that every developer must know by heart. Request architectural consulting for your IT projects from Chudovo!