Modernizing Enterprise Legacy Systems Without Full Rewrites: A Practical Architecture Playbook
In every enterprise engineering team, there is a moment in which the legacy system modernization topic starts looming in the department. Such a system has been in place for a long time, running billing, order management, or some other business-critical function. In most cases, the original architects are no longer in the company, the tests are sparse, and the documentation is lagging behind. Most of how this legacy app works is just tribal knowledge passed down from person to person.
The question is not if the system needs to change, but whether a full rewrite is actually the answer.
Most of the time, it isn’t.
This article walks through an incremental approach to legacy application modernization: how to extract functionality without a big-bang rewrite, how to wrap aging interfaces behind cleaner contracts, how to migrate toward cloud infrastructure without pulling the rug out, and how to refactor the codebase gradually while keeping things running. These approaches have been used in systems where downtime was unacceptable, and the cost of being wrong was a revenue impact or a compliance failure, not just a code smell.
Why Full Rewrites Keep Failing
Legacy systems often combine architectural problems with implementation ones. A messy data model, unclear procedures nobody fully understands, and a codebase without a clear structure that is really hard to maintain. Given that context, a full rewrite might sound like an opportunity to get rid of a legacy system that is often hard to work with.
The thing, however, is that those systems usually carry years of implicit business logic. Edge cases. Workarounds for bugs in upstream systems. Special handling for certain customers. Almost none of that is written down anywhere, and a lot of it only surfaces when the rewrite gets it wrong.
Let’s say you go with this approach. A new system is built, the release is done, and it immediately starts surfacing exceptions that the old system handled without anyone knowing. The company cannot afford the situation, so the solution is to keep the only system running as a fallback. Now you’re maintaining two systems. Joel Spolsky already described this dynamic in his post “Things You Should Never Do” back in the 2000s, so the rewrite problem isn’t new, but it keeps recurring because the pain of the existing system is visible, and the hidden complexity isn’t.
The Strangler Fig Pattern: A Starting Frame
One of the most useful strategies for incremental legacy system modernization is the strangler fig pattern, coined by Martin Fowler. It was inspired by some tree species that stay and grow around a host tree until they eventually replace it. To make the translation into the software development industry, you start building a new system incrementally around the legacy one. After each piece is in place, you shift the traffic from the legacy piece to the new one, test, and validate. Eventually, after some iterations, you will end up replacing the legacy system with the new one.
This translates directly into an architecture approach:
- Identify a bounded piece of functionality.
- Build the replacement alongside (or in front of) the legacy system.
- Route new traffic to the new path.
- Gradually shift existing traffic.
- Retire the old component after all traffic is successfully routed
The main advantage of this approach is that any change could be reversed with low effort. If something goes wrong after deploying the new piece, you route traffic back to the old system. This dramatically reduces risk if compared with a full rewrite.
Traffic routing at Step 3–4 is often handled with a feature flag or a simple proxy rule. Here’s a minimal example using a flag-based router in front of two implementations:
# nginx routing rule -- shift traffic gradually to new service
# Start at 5%, increase as confidence grows
upstream legacy_service {
server legacy-app:8080;
}
upstream new_service {
server new-app:8080;
}
split_clients '${remote_addr}AAA' $backend {
5% new_service; # 5% to new implementation
* legacy_service; # remainder to legacy
}
location /orders/ {
proxy_pass http://$backend;
}Should anything fail in the new system, you’re just one line away from putting the old system back to absorb 100% of traffic. Instrumentation on both upstreams lets you compare error rates and latency before committing to a full cutover.
Modular Extraction Strategy
Modular extraction means identifying parts of the legacy system that can be isolated from the core without breaking everything else, following a microservices adoption strategy. This is the first concrete step in any modernization plan for enterprise legacy systems.
What’s important to understand at this point is that not everything can be extracted in a clean manner. To find the best candidates, you should pay attention to those pieces that have the following characteristics:
- Clear input/output boundaries, so you can define what goes in and what comes out
- Relatively low entanglement with the rest of the system
- Reasonably well-understood behavior, even without formal test coverage
- A clear reason to modernize: performance, maintainability, and enterprise integration architecture
A practical way to find extraction candidates is to look at the deployment model. What needs to change independently? What’s behind random failures during a deploy? Those are usually the seams.
Once you’ve identified a module, a typical extraction sequence looks like this:
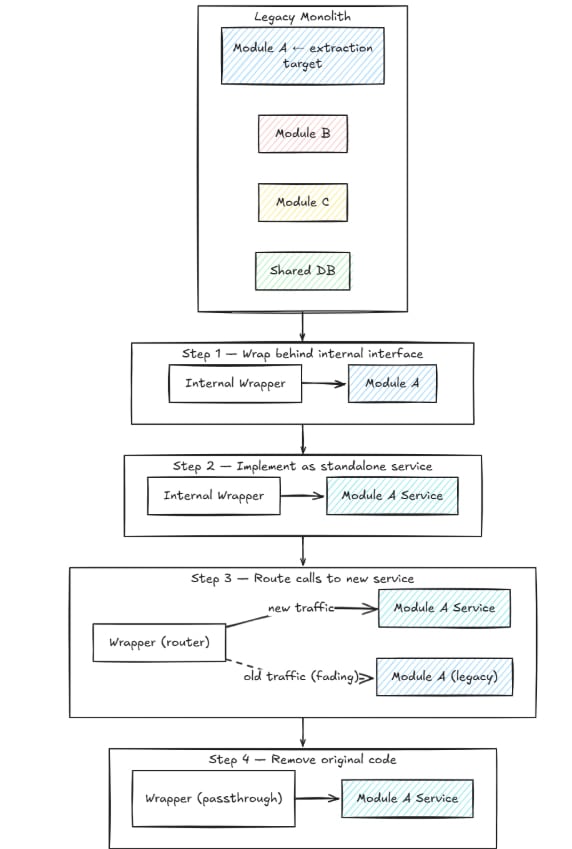
You can find this approach defined as the module-to-service path in service-oriented architecture migration. What’s important is to make the distinction from microservices-from-scratch: here, you’re following the existing decomposition of the system, not inventing a new one.
One last important thing to think about is shared databases. Both the monolith and the extracted service will almost always share a database initially, because changing both at the same time is too risky. That’s fine — database decoupling comes later, once the service boundary is stable.
API Wrapping for Legacy Applications
Having an API as a wrapper for your legacy applications is another valid strategy that you may adopt as a part of your company’s modernization plan. The idea is pretty straightforward: you basically build an API layer in front of your legacy system, in order to expose well-defined contracts for all the consumers while hiding the implementation details (I mean, the messy underlying code).
In practice, this approach is often overlooked, but most of the time results in the cheapest intervention with the widest impact. As explained above, one of its main purposes is to provide control over the external surface of the system. Should anything of the legacy application change, the API layer could absorb that without directly breaking the consumers. As a plus, instrumentation point — you can add logging, rate limiting, auth, and monitoring without touching the core system.
A typical setup follows this structure:
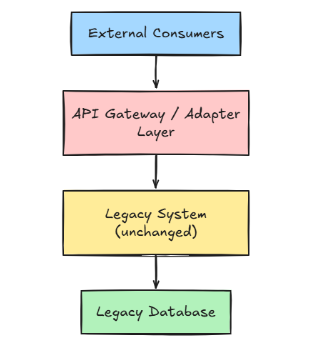
Say the legacy system has a SOAP endpoint:
<GetCustomerRequest>
<CustomerID>12345</CustomerID>
<IncludeHistory>true</IncludeHistory>
</GetCustomerRequest>The wrapper exposes a REST endpoint instead:
GET /customers/12345?includeHistory=trueLooking closer to the implementation, the wrapper could be considered a kind of translator. It will take the requests and translate them to the SOAP call, parse the response, and return a JSON to the consumers. They will never see the SOAP layer. If you finally decide to replace the legacy system, the contracts stay the same, so no changes are required for the consumers.
The main tradeoff here is latency. You’re adding a hop. For high-throughput, latency-sensitive paths, that matters and should be measured. For most enterprise internal APIs, the operational benefits outweigh the cost.

Now, here is the truth. Several organizations land at Phase 2 or 3 and stay there — the legacy database remains on-prem indefinitely because the migration risk isn’t worth it. That’s a legitimate outcome, not a failure.
The main challenge with hybrid setups is network and data sync. Having a cloud service that reads from an on-prem database has to pay for latency and introduces a single point of failure. To mitigate those risks, a change-data-capture layer is one of the cleaner solutions. Each change on the database — insert, update, delete — gets published to a Kafka topic.
A Debezium connector config for a PostgreSQL source looks roughly like this:
{
"name": "legacy-products_cart-cdc",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "legacy-db.internal",
"database.port": "5432",
"database.user": "replication_user",
"database.dbname": "products_cart",
"table.include.list": "public.products_cart,public.products_cart_items",
"topic.prefix": "legacy",
"slot.name": "debezium_slot",
"plugin.name": "pgoutput"
}
}Cloud consumers get subscribed to those topics in a cloud database or data warehouse. The legacy system keeps writing to its own database normally; it doesn’t know the CDC layer exists.
Of course, having two environments to monitor, patch, and secure adds operational complexity. This is often underestimated, so having good planning for this implementation is always necessary.
Incremental Refactoring
While modular extraction and API wrapping operate at the architecture level, incremental modernization of legacy applications is about making little improvements to the legacy code without changing its observable behavior. Every time someone touches a module to add a feature or fix a bug, they make a small improvement: rename a confusing variable, extract a long method, or add a test for a path that had none.
It’s slow and doesn’t produce a dramatic before-and-after metric, but this is where most of the actual technical debt reduction happens. By practicing Boy Scout coding —leaving it better than you found it— it compounds noticeably over 12–18 months on an active codebase.
Following this approach also contributes to a future module extraction. After reaching a point where it has reasonably clear interfaces, some meaningful test coverage, and minimal hidden state leaking across boundaries, extraction is much lower risk.
There are several patterns and techniques that you can rely on for this purpose. One of the most popular is to add a translation layer when the legacy system uses a domain model that doesn’t match the direction you’re heading — different terminology, different data shapes, implicit assumptions baked into the data model. This is known as the anti-corruption layer from Domain-Driven Design. Once implemented, you ensure new code uses the right concepts without being infected by the legacy model.
For teams dealing with high coupling and thin test coverage — which describes most legacy codebases — the Mikado Method is worth knowing. It’s pretty straightforward: whenever you identify a need for a refactor, do a first attempt at it. If everything compiles, all tests pass, and the system behaves as expected, you’re done. Should something fail, note every compilation error or test failure it causes, revert the change, then work through those prerequisites first by repeating the procedure above. Eventually, each prerequisite may uncover further prerequisites, building a dependency graph of the work ahead. You will end with a map of exactly what needs to change before the original change is safe to make — and because you’re always reverting before breaking the build, the main branch stays green throughout. It’s a slower process than just diving in, but on legacy code where a naive change can cascade in unexpected ways, the graph it produces is often the most accurate picture of the codebase’s internal dependencies you’ll get.
Practical Legacy Modernization Roadmap
Most of the time, these strategies tend to run in parallel, not in strict sequence. You may start doing incremental refactoring in one module, API wrapping on another, while planning a cloud migration for a third one. But to give a rough idea of what a modernization roadmap looks like, check out the graph below:
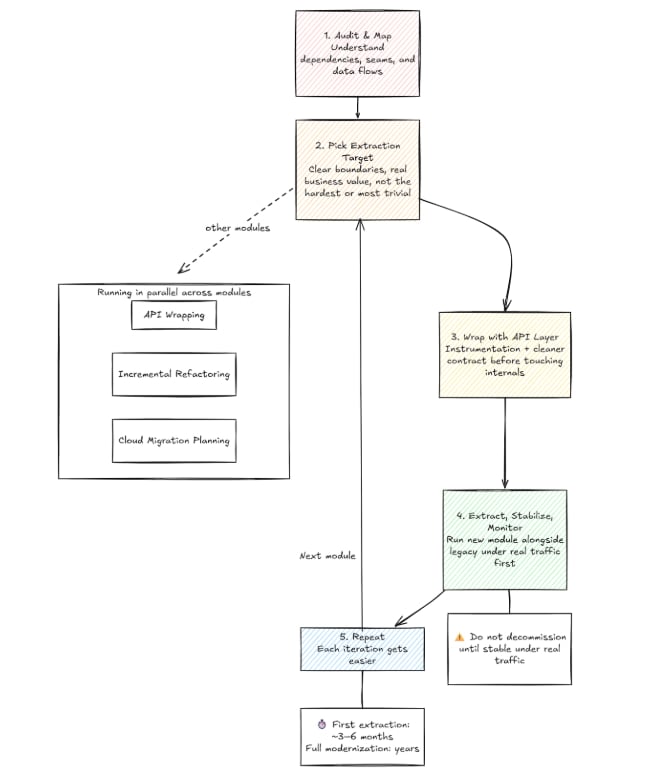
Wrap up
Modernizing enterprise legacy systems is mostly a sequencing problem. Rather than doing a full rewrite with the hope that everything will work as expected, it implies a methodical plan that involves picking the right seam, wrapping it, extracting it, and repeating, all of this while the system keeps running.
All the different techniques we discussed in the sections above — strangler fig, modular extraction, API wrapping, CDC-based sync, incremental refactoring, and the Mikado Method are helpful tools that you can use to accomplish the main objective. But none of them is a silver bullet on their own.
The main takeaway here is that in order to succeed, you need to plan and apply those tools in the order that matches your system’s needs and your team’s risk profile. Organizations that get this right tend to share one habit: they think about modernization like an ongoing engineering work, not a project with a fixed timeline. It’s a system that’s meaningfully less painful to work six months from now than it is today — and again six months after that.