The Rise of AI in Cloud-Native Software Development
AI integration with software started in the mid-50s, over 70 years ago. It began as a means to develop expert systems capable of solving problems that conventional algorithms had not yet addressed. From pattern recognition in media files to fully responsive AI chatbots, the potential applications of AI in software have exploded in academic research.
Due to all the advancements in AI research, corporations increased their investments in products that leverage AI and cloud architectures to solve problems. Today, some business cases run using AI workflows and the infrastructure of a cloud provider. For instance, we can build recommendation systems to recommend products to customers using the out-of-the-box Azure AI Foundry large language model (LLM) and other auxiliary services such as .NET serverless functions and databases. We’ll see a practical example of that in further sections.
Integrating AI with .NET and Azure Cloud
A critical component of our recommendation system’s AI .NET cloud architecture is the prompt. A prompt is a form of communication with the LLM. For instance, we can ask the Azure AI Foundry cloud service to generate a list of recommended products based on a customer’s previous purchases and preferences.
However, many models might answer this ineffectively if we don’t process the input data effectively, don’t prompt correctly, or don’t give contextual information to the LLM.
Prompt Engineering Integration with Cloud
As mentioned, the interaction between the user/developer and the LLM is via a prompt. Hence, the LLM processes the request and searches its internal knowledge for the best answer, based on probability. However, not providing clear instructions might affect the assertiveness of the answers.
To improve assertiveness and enhance the user experience, we can utilize prompt engineering guides from Azure OpenAI. This approach structures the prompt in a format that is more digestible for the LLM, thereby increasing the likelihood of a good response.
For instance, few-shot prompting is a technique that attempts to improve the LLM’s answers by providing examples of good answers, thereby limiting the LLM’s responses. On the other hand, zero-shot prompting suggests that the prompt doesn’t contain any examples of an ideal answer, letting the LLM decide it.
It’s possible to integrate prompting with virtually any language capable of making an HTTP call, as most current AI models have a public API to interact with. In addition, some frameworks offer out-of-the-box integrations with various LLMs. For instance, the Azure OpenAI project for .NET and the Spring AI project for Java have built-in libraries that enable interaction with various models, including GPT, Ollama, and Mistral, among others.
Prompt engineering will be at the core of our .NET cloud architecture, recommending products to users.
Retrieval-Augmented Generation (RAG) and Cloud Vector Databases
Put simply, retrieval augmented generation (RAG) is the process of extracting information from one place, transforming it into tokens, and loading it into another place. For instance, we can extract the data from a marketing book in a document database hosted in Azure and transform it into tokens. Each vector could represent a word or an entire sentence, depending on how we decide to split the text. Then, we could store all extracted vectors in a vector storage like Azure AI Search. After that, we have a storage containing the book information in a format that an LLM can process easily.
After extracting, transforming, and loading, we can use similarity searches to find vectors that better help answer the questions posed in the prompt. For instance, after loading an entire book into a vector store, we can use marketing strategies from it to better recommend products.
Serverless Functions with Azure serverless services
Serverless functions can help us validate and transform data in latency-critical pipelines. In the case of a recommendation system, the process is asynchronous, making it beneficial for this kind of work. We can utilize serverless functions as units of validation and transformation in such a workflow, making it cost-effective as well.
For instance, we can define a serverless function to be the validator. In that case, its only responsibility is to validate the input obtained from some data source, such as a database, or user input. Hence, improving the amount of incorrect data that reaches the LLM enables it to enhance its accuracy.
Additionally, we can define a transformer serverless function that has the responsibility of transforming an input payload into another, which helps the LLM digest the data.
Event-Driven Pipelines using Azure Storage Queues
The final component of our cloud architecture is queues, which enable us to implement more resilient asynchronous workflows. With queues, we can automate the transfer of data from one place to another using notification services such as Azure Storage Queues. Hence, if something changes in a database, we’ll be notified in another system so that we can take action. For instance, if a customer bought one product today, that data modifies a relational database that automatically notifies our recommendation system workflow. Thus, ensuring that the input data for the LLM is the most recent one.
A Real-World Example of Cloud Architecture Integrated with AI
Now, let’s examine what a cloud architecture integrated solution looks like to address the recommendation problem. Below is the high-level diagram of how the cloud services mentioned so far connect.
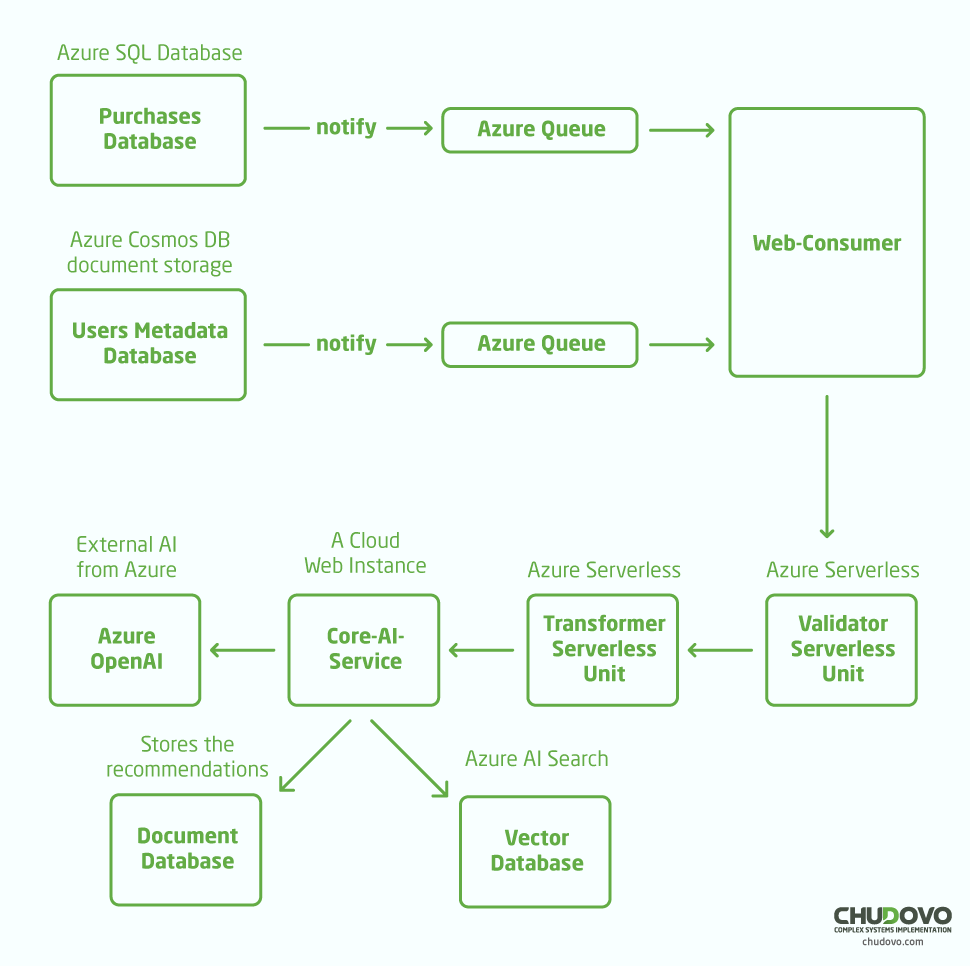
Let’s break down the diagram into a list to understand it better:
- The first step is to obtain data from a source. In our case, we get the data from the primary source of purchases in the system, the purchases database. Additionally, we obtain more metadata about user preferences, such as the number of times a user visited a product, or whether they liked or reviewed it.
- With the purchases and users’ preferences, we notify a .NET web application asynchronously via Azure Queues.
- The web-consumer application simply receives events from both databases and starts the serverless unit chaining pipeline. The first function validates the data obtained from the databases, checking if it’s in the expected format, for instance. The second function transforms the data into a more digestible format for the next application, such as parsing from SQL relations and CSV to JSON.
- The core-ai-service is another .NET web application that integrates with Azure OpenAI, the Azure AI Search database, and another document database to store results.
- It first executes similarity searches in Azure AI Search to retrieve similar information from the provided data source. For instance, here we could have stored the marketing book mentioned earlier, in the form of vectors, for the AI to recommend products that align with the book’s author.
- Then, it goes to Azure OpenAI, through a prompt defined in code. After processing the response, we store the result in a database available for another application to use and retrieve the recommendations.
Conclusion
In this post, we’ve seen how to create a simple .NET cloud architecture LLM to recommend products for users in an e-commerce.
Contact our team for comprehensive cloud app development services with .NET.