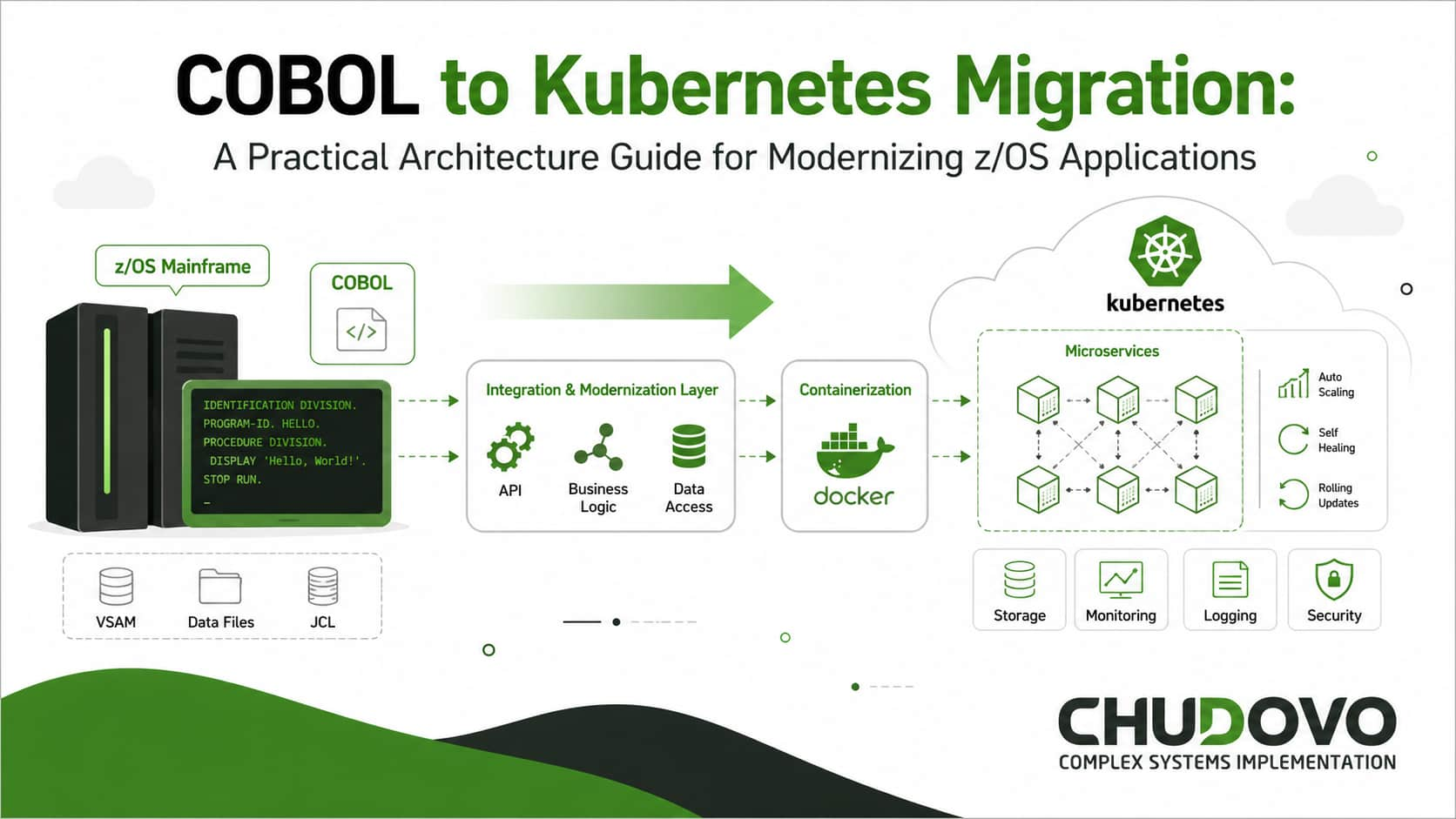
COBOL to Kubernetes Migration: A Practical Architecture Guide for Modernizing z/OS Applications
COBOL on z/OS wasn’t built to be migrated. It was built to be correct, fast, and long-lived. Systems that have been in place for 30 years are still there because they work, which is also what makes them hard to move.
Several development teams get involved in mainframe modernization projects that usually run out of money before they run out of scope. Most of the time, this is due to the same pitfalls.
Whether you’ve been involved in that situation or you’re trying to avoid it, this guide covers what that project probably needed. In the sections below, we’ll walk through a realistic architecture for moving COBOL workloads to Kubernetes. Our main focus will be to approach this legacy modernization without triggering a full rewrite and without taking down systems that process millions of transactions daily.
Why Mainframe to Kubernetes Migration Usually Fails
These failures aren’t random. They usually fall into three recognizable patterns, and two of them are architectural decisions made early in the project.
Let’s start with the most common one: the full rewrite trap. If we have to describe it in a few words, it will look like the following:
- Someone scopes the COBOL codebase, multiplies by a conversion factor, and proposes rewriting everything in Java or Go.
- Eventually, the new code reaches production, and edge cases surface that nobody anticipated and that were handled by 1987-era patches nobody remembered to port.
As you can see, the main problem with the full rewrite approach is that it tends to ignore decades of business logic embedded in the code. COBOL programs are often correct in ways nobody documented, because the documentation was the production behavior
The lift-and-shift mistake goes the other direction. Someone says, “Let’s wrap the compiled COBOL in a container”, and they call it “modernized”. At the runtime level, nothing really changes. The truth?. You’ve added Kubernetes operational overhead on top of a system still depending on z/OS semantics.
Finally, the strangler pattern applied too aggressively is subtler. This happens when teams extract a component, build a microservice, and declare success without accounting for shared transaction state, DB2 cursor scope, or MQ message sequencing. The extracted service works in isolation. It breaks under load when it starts interacting with the systems it was supposed to replace.
How to Migrate Mainframe to Cloud Without Rewriting
We can safely assert that most of the current existing legacy COBOL codebase in production has been there for more than ten years. And we can also assert that every single one of such codebases contains things written in the past that nobody remembers: date handling logic that survived Y2K for specific reasons; transaction rollback sequences that are correct because they were debugged against real failures.
In the section above, we’ve already discussed the pitfalls of a full rewrite. Teams that skip this reality check typically spend 18 months rewriting and another 18 months chasing regressions.
The question, now, is how to approach the migration. In Chudovo’s experience, refactoring COBOL monolith components incrementally preserves verified production behavior while allowing the teams to properly test specific parts of the application at a time, detect critical issues, and even ensure a safe and quick rollback in case something goes wrong.
A final useful framing: treat the existing COBOL as the most detailed specification you have. Your job is to perform service decomposition into deployable units. Do not replace what it says.
Incremental Strategy for COBOL Cloud Migration Using the Strangler Pattern
The strangler pattern is a migration strategy where new functionality gradually replaces old without a big-bang cutover. The name comes from the fig tree that grows around a host. In practical terms, you don’t migrate the whole system at once. You identify a bounded capability, route traffic to a new implementation, validate it, and retire the old path.
In mainframe migration, this pattern is the right model to migrate COBOL applications to Kubernetes. The approach is quite straightforward: you add an API layer in front of the existing z/OS system, then incrementally redirect traffic to containerized services as each one is validated. The original z/OS system handles less and less load over time until it can be decommissioned. This way, the mainframe remains available as a fallback throughout the migration.
This section serves as a practical mainframe strangler pattern example.
Expose the Monolith via API (API Enablement)
The first step before routing traffic away from CICS is to create a seam: a thin API gateway layer, deployed on a distributed platform. It will receive inbound calls and forward them to the z/OS backend. Nothing changes in the COBOL programs yet. This step instruments the system and gives you the traffic visibility you’ll need later. IBM z/OS Connect is one option here; there are others depending on the CICS version in use.
Identify Decomposition Candidates
Not all COBOL programs are good candidates for extraction. Good candidates share some common traits:
- Clear input/output contracts with no shared VSAM dependencies
- Batch jobs that don’t depend on real-time CICS state
- Lookup or validation logic with no write-side effects
Poor candidates are tightly coupled to DB2 unit-of-work scope, to CICS commarea state, or to JES2 job dependencies that are difficult to replicate outside the mainframe.
Extract and Containerize
After you find a suitable candidate, the next step is to extract the business logic into a standalone service. Chudovo’s engineering team uses a pattern where COBOL source is transpiled to Java (via tools like Micro Focus Enterprise Developer or IBM Application Discovery) and then refactored to remove z/OS-specific runtime calls. The resulting service is containerized and deployed to Kubernetes.
Route and Validate
The right approach for this step is to split the traffic. The API gateway routes a percentage of calls to the new container service. Responses from both paths are compared in real time. This dark-launch approach means the new service earns trust before it takes full production load.
Retire the z/OS path
Once the containerized service demonstrates parity, traffic shifts fully. The COBOL program is decommissioned from CICS.
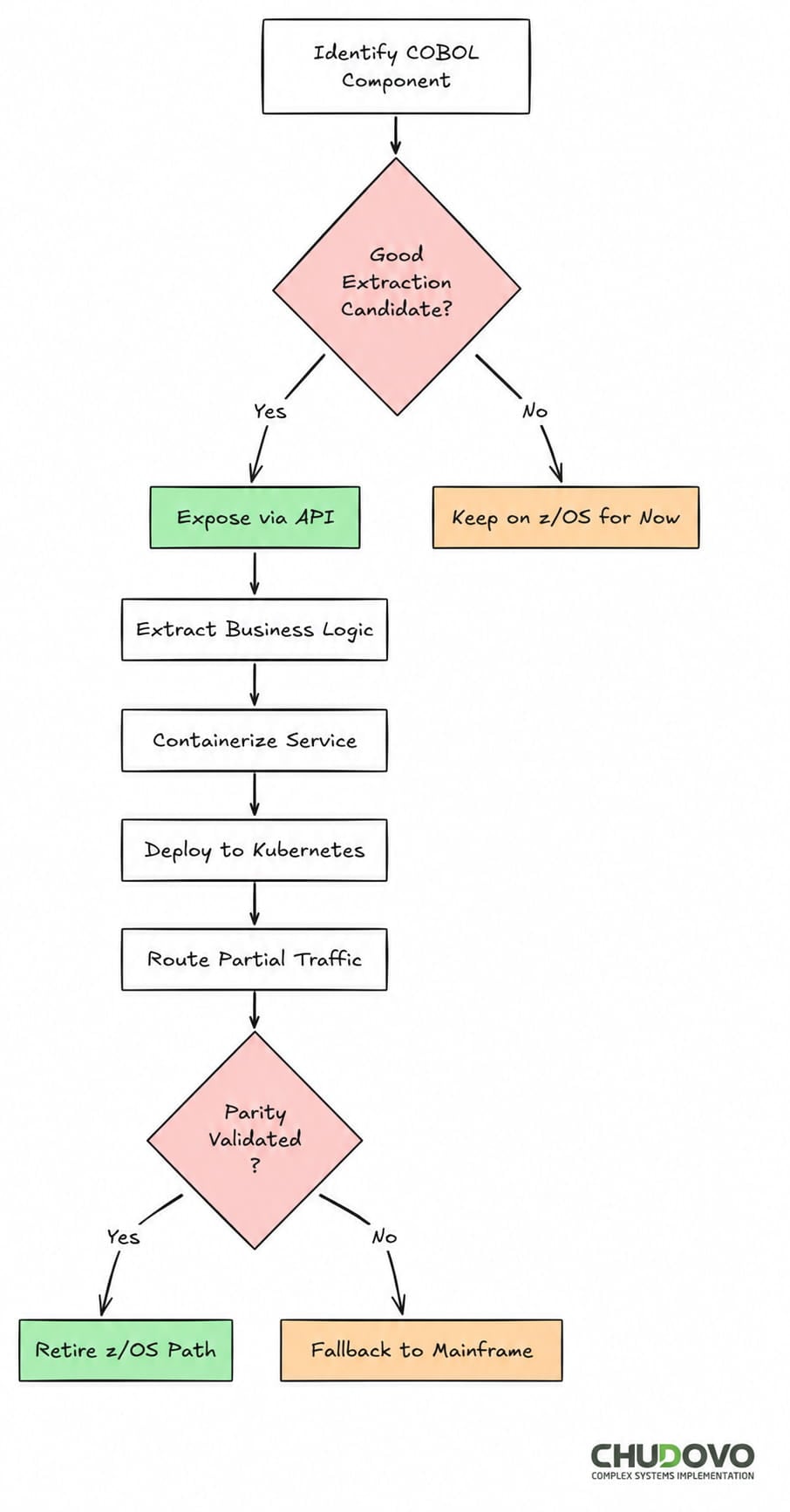
Can COBOL Applications Run in Containers?
Tools like Micro Focus COBOL for JVM or GnuCOBOL make containerizing legacy applications and mainframe workloads possible.
Should you do it? Well, it depends on what you’re trying to achieve. Running compiled COBOL in a container gives you deployment flexibility. It doesn’t give you horizontal scalability, API-first design, or independent deployability. You’re running a monolith in a pod.
Small, well-isolated programs (such as a utility calculation, a date conversion routine)may find this approach is pragmatic and fast. For core transactional programs entangled with CICS state and DB2 cursor management, refactoring is necessary regardless of the runtime.
Mainframe Modernization Architecture for z/OS in Practice
A z/OS to cloud migration architecture usually follows the structure below:
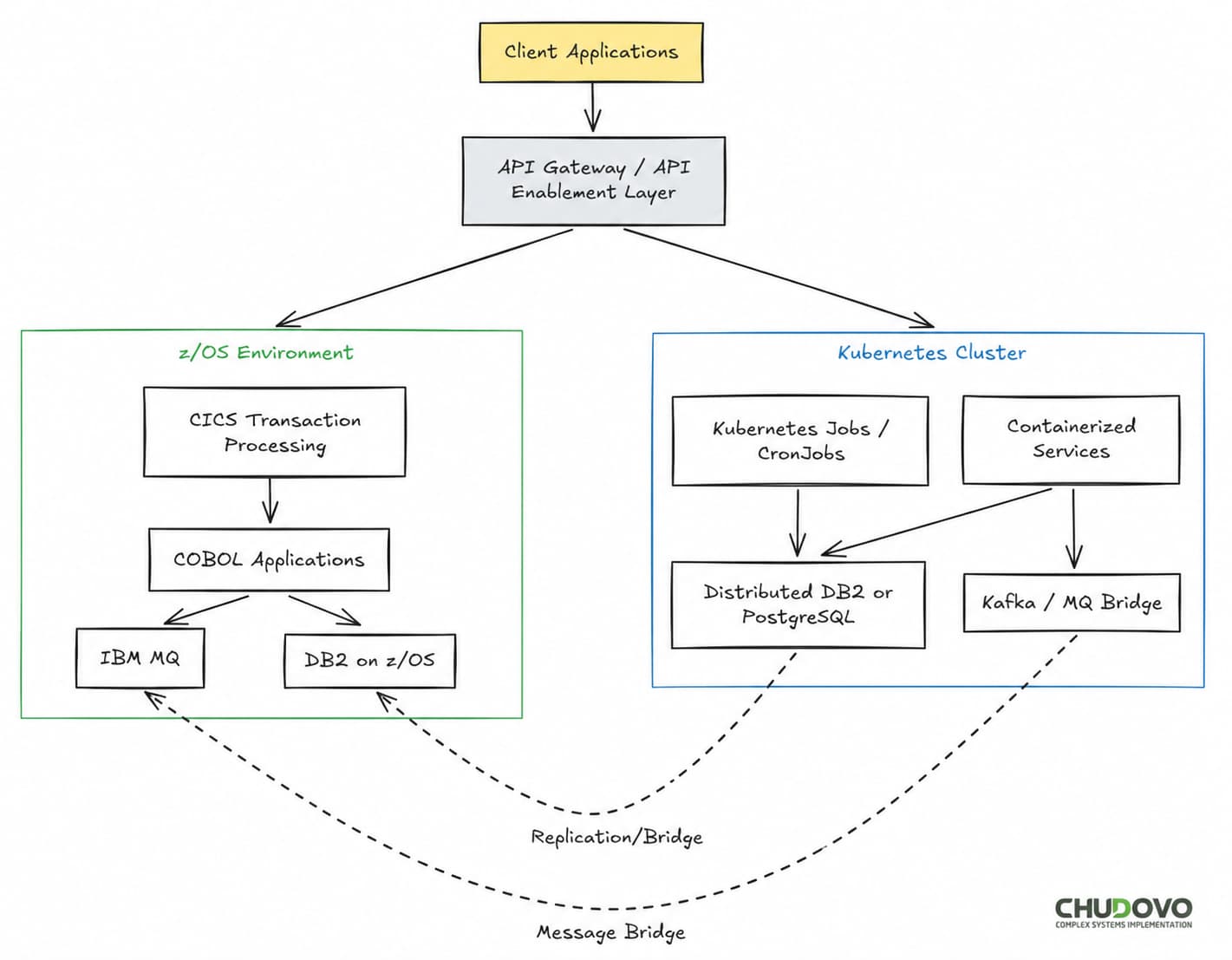
In most z/OS modernization projects, DB2 is the last thing to move. The risk of migrating DB2 data while COBOL programs are still reading and writing it is high. A common intermediate state is a DB2 bridge: containerized services write to a distributed DB2 instance, which replicates to z/OS DB2 using IBM’s own replication tooling. Over time, z/OS DB2 becomes read-only, then decommissioned.
Deployments in Kubernetes typically follow patterns like the one below.
apiVersion: apps/v1
kind: Deployment
metadata:
name: account-service
spec:
replicas: 3
selector:
matchLabels:
app: account-service
template:
metadata:
labels:
app: account-service
spec:
containers:
- name: account-service
image: account-service:latest
ports:
- containerPort: 8080Here’s what the end-state looks like for a mixed z/OS / Kubernetes environment mid-migration:
| Layer | z/OS (legacy) | Kubernetes (target) |
| Transaction processing | CICS | Container-based REST or gRPC services |
| Batch | JES2 / JCL | Kubernetes Jobs or CronJobs |
| Data persistence | VSAM, DB2 on z/OS | Distributed DB2 or PostgreSQL |
| Messaging | IBM MQ | Message queues (Kafka, MQ) bridge |
| Integration | COBOL subroutines | Internal APIs |
From CICS to COBOL Microservices: A COBOL to Microservices Architecture Example
Consider a customer balance inquiry. On z/OS, this runs as a CICS transaction processing flow: a client sends a request, CICS dispatches a COBOL program. The program issues a DB2 SELECT, formats the COMMAREA response, and returns. The round trip takes 8–20 milliseconds.
How can this be migrated to a containerized service?
Usually, Chudovo’s team translates this to Java, removes the EXEC CICS RETURN, replaces the EXEC SQL block with JDBC, and wraps the logic in a Spring Boot REST controller. A GET /accounts/{id}/balance endpoint is exposed, allowing Kubernetes to handle routing, scaling, and container orchestration. The structural logic is identical. The runtime is entirely different.
For example, given this simplified version of what the COBOL looks like:
IDENTIFICATION DIVISION.
PROGRAM-ID. BALQRY.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-ACCOUNT-ID PIC X(12).
01 WS-BALANCE PIC S9(13)V99 COMP-3.
01 WS-SQLCODE PIC S9(9) COMP.
LINKAGE SECTION.
01 DFHCOMMAREA.
05 CA-ACCOUNT-ID PIC X(12).
05 CA-BALANCE PIC S9(13)V99 COMP-3.
05 CA-STATUS PIC X(2).
PROCEDURE DIVISION.
MOVE CA-ACCOUNT-ID TO WS-ACCOUNT-ID
EXEC SQL
SELECT BALANCE
INTO :WS-BALANCE
FROM ACCOUNTS
WHERE ACCOUNT_ID = :WS-ACCOUNT-ID
END-EXEC
IF SQLCODE = 0
MOVE WS-BALANCE TO CA-BALANCE
MOVE 'OK' TO CA-STATUS
ELSE
MOVE 'ER' TO CA-STATUS
END-IF
EXEC CICS RETURN END-EXEC.The implementation in Java will look slightly as follows:
@RestController
@RequestMapping("/accounts")
public class AccountController {
private final AccountService accountService;
public AccountController(AccountService accountService) {
this.accountService = accountService;
}
@GetMapping("/{id}/balance")
public ResponseEntity<AccountBalanceResponse> getBalance(@PathVariable String id) {
BigDecimal balance = accountService.getBalance(id);
if (balance != null) {
return ResponseEntity.ok(new AccountBalanceResponse(id, balance, "OK"));
} else {
return ResponseEntity.status(HttpStatus.NOT_FOUND)
.body(new AccountBalanceResponse(id, null, "ER"));
}
}
}Failure Points and Mitigation
Like any other software development, a migration of a legacy COBOL app to Kubernetes usually raises some common concerns that should be addressed:
Transaction Scope Mismatch
CICS manages its own unit of work. When you extract a service to Kubernetes, that implicit transaction boundary disappears. If the COBOL program issues multiple DB2 writes under a single CICS UOW, the containerized version needs explicit transaction management. Teams that miss this may end up with partial writes under load.
One common approach to prevent this issue is to use the saga pattern for distributed transactions. With it, each step has a compensating transaction. It adds complexity, for sure, but it’s the honest model for distributed systems.
Batch vs. Real-Time Processing
JES2 batch jobs have scheduling semantics that Kubernetes CronJobs don’t replicate. A JES2 job has priority, job class, and initiator affinity. A Kubernetes CronJob has a schedule and a pod template. In some cases, with complex dependency chains (i.e., when job A must complete before job B starts), you’ll need an orchestration layer. Apache Airflow and Argo Workflows are common choices.
DB2 Cursor Scope
Some COBOL programs open DB2 cursors and hold them across multiple CICS calls. Each container instance is stateless: cursor state is gone when the request ends. For those programs, you need to think about refactoring before extraction.
Character Encoding
z/OS uses EBCDIC. Everything else uses ASCII or UTF-8. For data coming out of DB2 on z/OS, VSAM files, or MQ queues, you need to ensure encoding conversion. This consistently produces production bugs in migrations when developers treat it as a minor detail (typically showing up as corrupted data in string comparison logic or decimal point handling in numeric fields).
Conclusion
COBOL to Kubernetes migration is more than a single project. It involves an architectural transformation that needs to be done one service at a time. This leads to a process that may take months or even years until full completion.
Teams that ignore these constraints end up relying on luck. Sometimes things hold together for a while. More often, they don’t. In such cases, developers are left dealing with hotfixes and rollbacks under pressure. That’s an expensive way to learn the lesson.
There are some key decisions that actually determine success, which are the following: what to extract first, how to handle the DB2 migration and how to manage batch job dependencies. Others may appear depending on your company’s business logic.
Those decisions should be made by engineers who understand their specific codebase. There’s no universal answer.
The strangler pattern gives you a framework for doing this without taking on the full risk of a rewrite. It’s a structure for making those decisions incrementally, with fallbacks, instead of all at once. COBOL isn’t the problem. The deployment model is.