Designing Automation for Regulated Industries: Balancing Compliance and Innovation
Most automation is optimized to improve performance. It implies that development teams have to optimize processes to move data faster, reduce manual steps, and cut error rates. In industries like finance, healthcare, insurance, or energy, that argument still holds.
But in those industries, a mistake during a process in a loan origination system or a clinical data pipeline doesn’t just produce a bug report. It can trigger a regulatory finding, a breach notification, or a fine. This is where regulatory compliance automation becomes a design concern, not just an operational one.
Throughout the following sections, we’re going to expose structural patterns that matter when designing automation for regulated industries. We’ll share Chudovo’s experience from engagements with teams in charge of risk management in automation, and discuss how they approach topics such as auditability, policy enforcement, and building systems that someone other than the original author can verify.
What “Observability” really means
In classic system architecture, “Observability” is about keeping such a system running, not explaining what it did. This results in logs being usually scoped to operational questions:
- Is the service up?
- Is latency acceptable?
- Are there any errors?
Automation in regulated industries works a little bit differently. Here, logs that only “show what happened” are not enough. In those industries, explaining who authorized the operation, under what policy, and whether that policy was current at the time of the decision, is even more important than the operation itself. These goals don’t collapse into a single layer cleanly. The real challenge is to separate the concerns of each and find the right balance between both. This usually matters more than optimizing either one in isolation.
Enterprise Automation Governance
Enterprise automation governance is not optional in regulated systems. It means actions can be taken because a defined rule permits them, following a policy-driven automation approach, and that those rules are versioned, auditable, and readable by someone outside the engineering team.
Consider a simple approval workflow in a financial context. An automated system routes transactions for secondary review based on risk score thresholds. If those thresholds live in application code, changing them requires a deployment. That deployment may not be logged in a way that satisfies audit requirements. A regulator reviewing the system needs to trace what threshold was active on a specific date. “Check the git history” doesn’t work in most audit contexts.
When decisions need to be explainable outside the engineering team, then governance in enterprise automation becomes critical.
A more defensible automation governance model externalizes policy. Thresholds live in a policy store: something like Open Policy Agent or a purpose-built rules engine. Every evaluation records the policy version consulted. The automation itself asks “is this action permitted?” and acts on the answer. The policy layer accumulates a verifiable history, separate from the application’s deployment cycle.
Chudovo’s team often sees a pattern like the one below in governance strategies for enterprise automation. It does not need to be sophisticated, but explicit about something most application code leaves buried in logic.
async function evaluateAction(actionType, context) {
const response = await fetch("http://policy-engine/v1/data/finance/approve", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ input: { action: actionType, context } }),
});
// In regulated contexts, a failed policy check must never default to permissive.
// Fail closed: if the engine is unreachable or returns an error, deny the action.
if (!response.ok) {
logAuditEvent({ action: actionType, decision: false, policyVersion: null, context });
throw new Error(`Policy engine returned ${response.status}. Action denied.`);
}
const result = await response.json();
// Log policy version for audit trail
logAuditEvent({
action: actionType,
decision: result.result,
policyVersion: result.policyVersion ?? null,
context,
});
return result.result;
}The example above is not meant to be production-ready. Policy versioning is not always returned by the policy engine and often needs to be injected explicitly. OPA bundle deployments expose a bundle version that works well for this. Commit hashes are another option technically, but they’re opaque to auditors. A version identifier is only useful in an audit if the compliance team can read it without opening a terminal..
Here’s how the full flow will look once implemented:
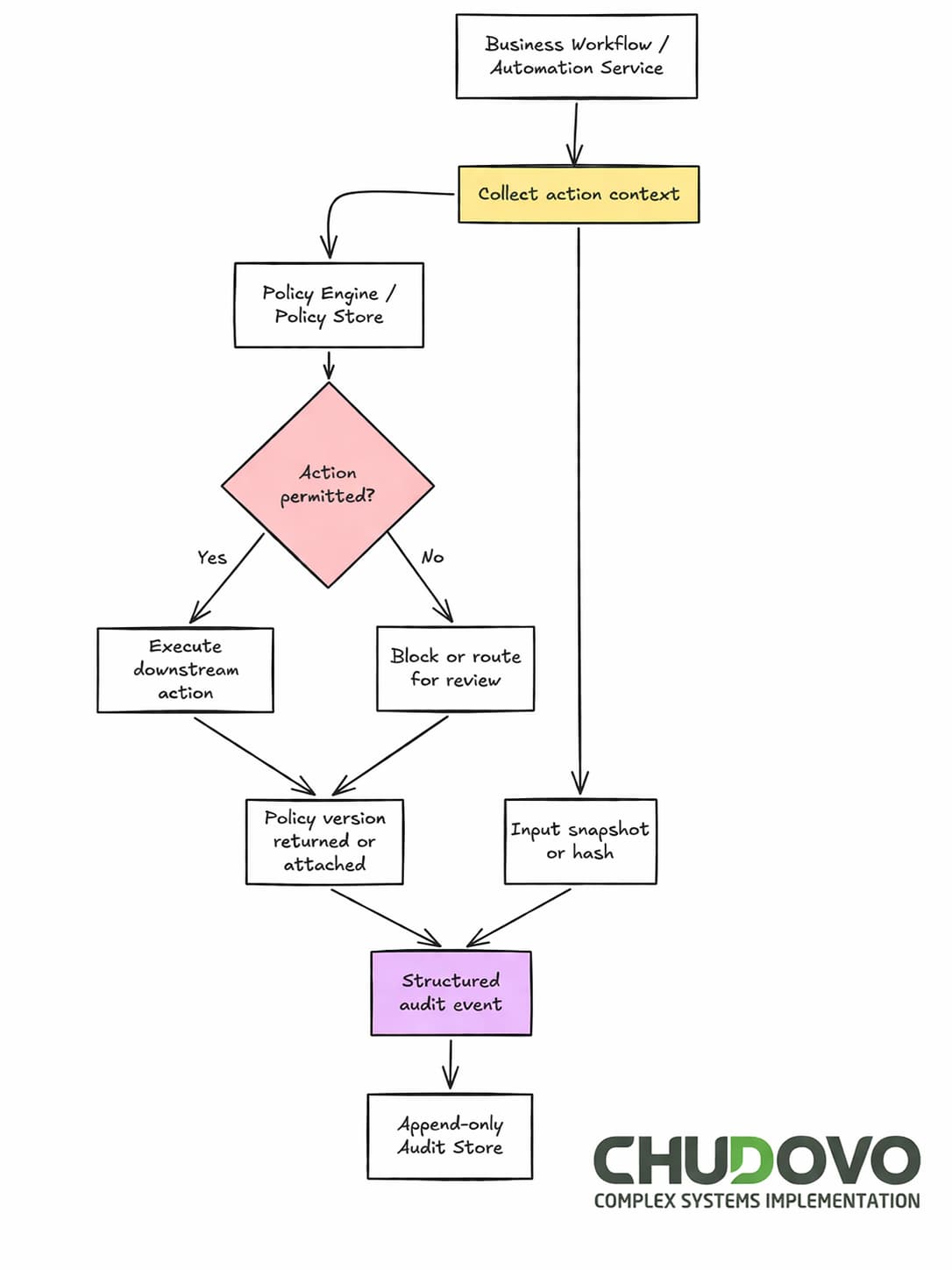 Auditability in Automated Systems
Auditability in Automated Systems
When IT teams are asked about audit trails of their systems, the first common answer tends to be “We have logs”. While this may work in some cases, regulated industries require thinking and design auditability as a first-class concern.
An effective regulatory compliance automation demands that your system is able to know not only what action was taken, and when, but also what state triggered it and what rule authorized it. Also, in most cases, it is mandatory to acknowledge whether the data was correct at the time of the decision and who or what initiated the chain of events.
While logs serve for the first question, the others require deliberate design. Below is a rough comparison of operational observability versus compliant automated audit trails:
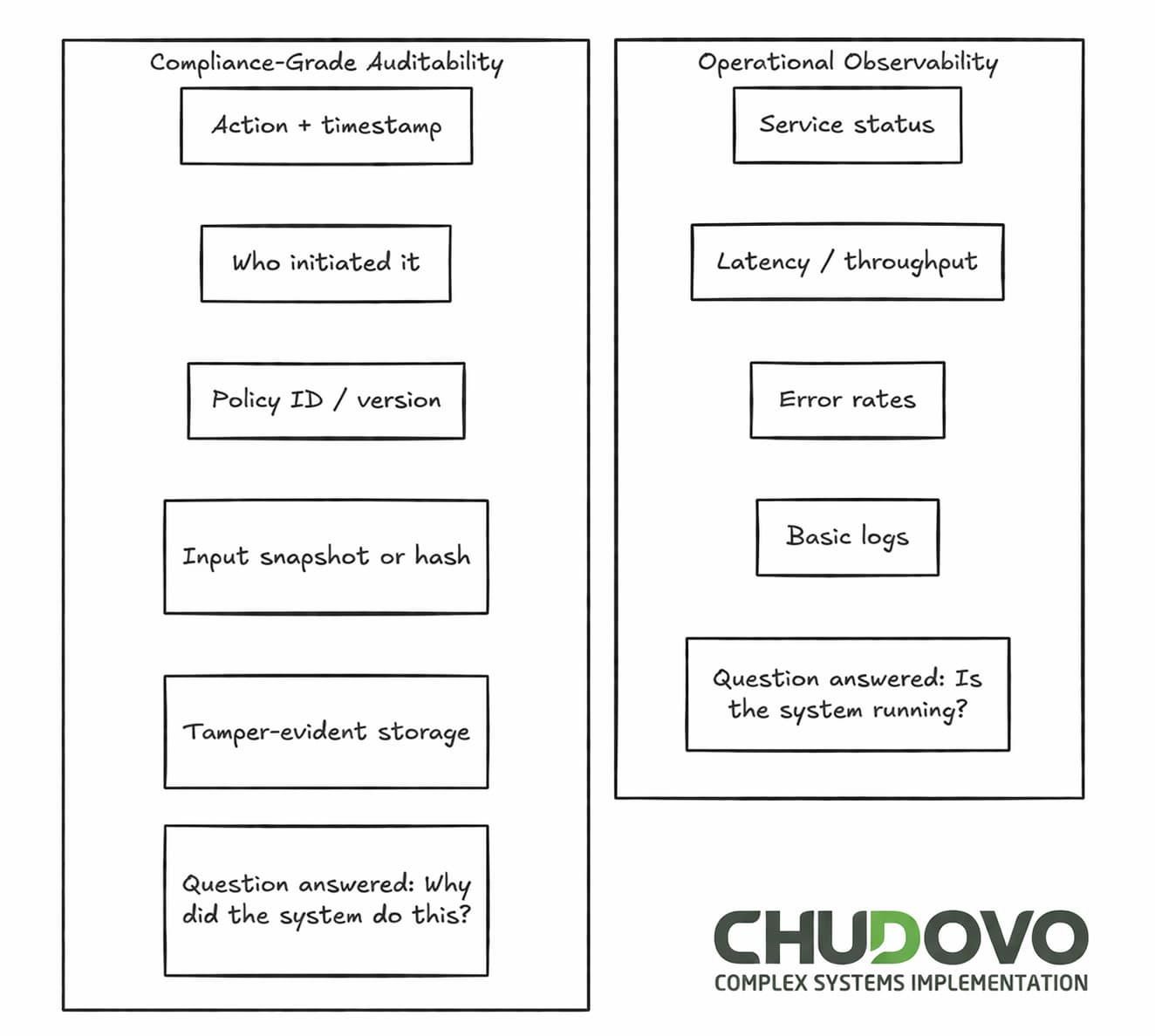
There are multiple ways you can collect this information. A commonly used one is to have an event-based logging pattern at the automation boundary. Under this approach, your system will emit a structured event before and after any transaction. Such an event will capture all the relevant fields you need to build the audit trail: the input state, the policy version consulted, the actor identity (user, service account, or scheduled job), and the outcome. A common approach followed by Chudovo’s team is to have an event builder that can be called each time you need to emit the event mentioned above:
// Structured audit event emitted at the automation boundary
function logAuditEvent({ action, decision, policyVersion, context }) {
const event = {
eventId: crypto.randomUUID(),
timestamp: new Date().toISOString(),
actor: context.serviceAccount ?? context.userId,
action,
decision,
policyVersion: policyVersion ?? "unknown",
inputHash: hashPayload(context), // tamper detection only
// inputSnapshot: context, // full reconstruction -- store separately if required
};
auditStore.append(event); // append-only
}This approach gives you reconstruction capability, not just a record. It helps build real automated audit trails.
As shown in the table below, a typical log often lacks the information required for a compliance-grade audit trail. However, implementations to get some parts of the right column might be expensive. Much of it comes down to what you decide to log, not whether you invest in specialized infrastructure.
| Audit Dimension | Typical Log | Compliance-Grade Audit Trail |
| What happened | Action name, timestamp | Action name, timestamp, idempotency key |
| Why it happened | Often absent | Policy ID, version, evaluation result |
| Who triggered it | User ID or service name | Full actor chain including upstream callers |
| Data at decision time | Rarely captured | Snapshot or hash of input payload |
| Tamper evidence | None | Append-only store, cryptographic chaining |
Compliance Automation Frameworks and Automated Compliance Monitoring: Options and Tradeoffs
Different approaches to regulatory compliance automation come with tradeoffs in flexibility, auditability, and operational complexity. The right compliance automation frameworks, often categorized under regulatory technology (RegTech), depend on your regulatory context, existing tooling, and how often the compliance surface changes.
Rule-based engines (Drools, OpenL Tablets, custom DSLs) give compliance teams a way to define rules without touching application code. Useful when business rules change frequently and require non-developer review. They can also grow quickly. Systematic testing of rule interactions is harder than it looks at the start.
Open Policy Agent and Cedar, among others, elevate policy to the status of a primary software component (Policy-as-code). Policies are version-controlled and testable. This suits engineering teams, who are comfortable maintaining policy code with the same rigor as application code. The tradeoff: it requires that discipline to actually exist. Treating policy files like configuration files defeats the point.
Automated compliance monitoring works at a different layer as part of broader compliance monitoring systems. Rather than enforcing rules at execution time, it checks whether the system state conforms to expectations. Cloud-native options (AWS Config, Azure Policy) fit here, as do custom monitoring jobs that query state and emit findings. These tools operate primarily at the infrastructure and configuration level, not at the business logic layer. This approach is reactive, not preventive, but it’s a practical starting point when the enforcement layer isn’t ready yet.
Most architectures combine all three. Preventive controls at execution time, detective controls for drift, policy-as-code for the things that need audit-grade traceability.
How to Balance Compliance and Innovation
Compliance requirements do slow some things down. Auditability instrumentation takes time to build correctly. Policy review cycles add latency. Infrastructure changes need more sign-off. In already-running systems that need to introduce compliance flow, the thing gets worse: it means touching core data flows, adding middleware that wasn’t designed for the job, and hoping the existing logs are sufficient (They usually aren’t.).
Balancing compliance and innovation in automation is less about tradeoffs and more about sequencing architectural decisions correctly. A more productive framing is to think of the governance layer as a product with its own users. The audit trail has consumers: auditors, compliance officers, and regulators. Their requirements can be designed in the same way as any other user’s requirements. The policy layer has consumers, too.
Teams that approach it this way report a slower start and a faster steady state. The governance infrastructure pays back when the next regulatory change arrives. Instead of a scramble to reconstruct what the system was doing six months ago, it’s a policy update and a test run.
Automation Governance Models: What Fails and How
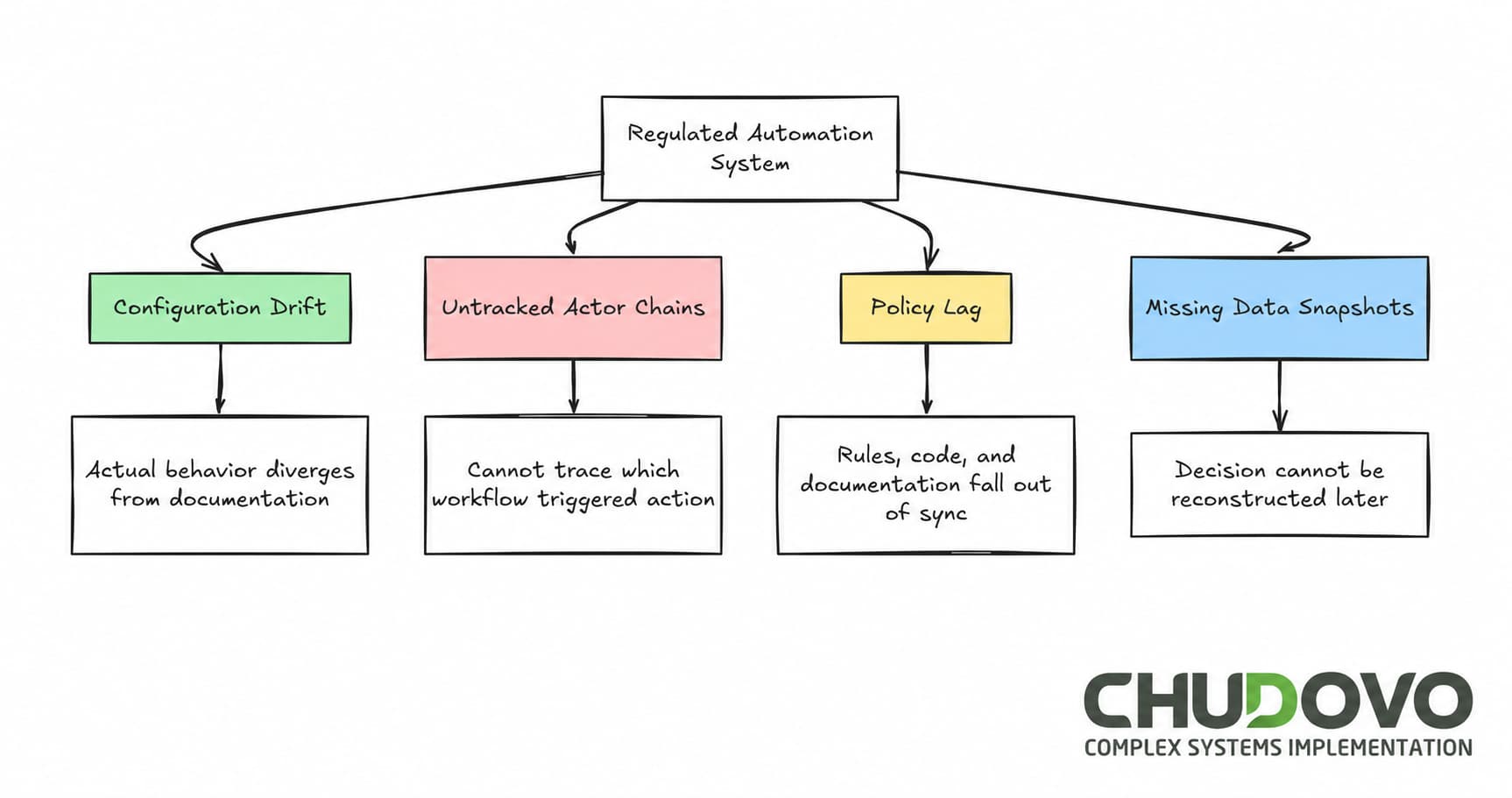
Regulated automation systems fail in predictable patterns. Four show up repeatedly.
Configuration drift
In some cases, the system was compliant at launch. Later on, thresholds were adjusted informally over time. Environmental changes accumulated. By the time an audit comes around, the system’s actual behavior no longer matches its documentation.
Untracked actor chains
An automated job runs as a shared service account. Multiple workflows share that account. After the fact, tracing which workflow triggered a specific action is not possible.
Policy lag
If the regulatory requirements change, the application code needs to be updated. But also the documentation. When the development team only takes care of one of the parts, the system and its paper trail end up describing different things.
Missing data snapshots
This may happen when a log records that a decision was made, but not what data informed it. In the event the underlying data has since changed, reconstructing the decision is not possible.
Look at the graph below for a quick summary of the issues exposed above:
Practical Starting Points
In the previous sections, we’ve exposed some architectural patterns that can be used to tackle automation in regulated industries. It does not pretend to be a complete solution. It’s just a set of decisions that keep options open.
For teams beginning this work, a sequence that tends to hold is:
- Start by identifying every point where automated actions touch regulated data or trigger downstream effects. This sets clear automation boundaries and avoids false expectations.
- Define audit requirements before building. The company’s compliance team needs to be involved to list all the information an auditor actually needs to see, not what you think they’ll ask for.
- Move to the build phase. Start by picking one external policy store and use it consistently (consistency matters more than the specific tool you choose). Then, build append-only audit logs from day one (this is painful to add later).
- When the implementation is done, run a tabletop exercise: assume an audit started this morning, and try to answer every question from the table above using only what your current logs contain. Don’t wait until a real audit comes up.
Remember this: your main goal is to build a system that’s explainable from day one, with clear paths to improve it. Not a complete compliance architecture before anything ships. For teams implementing automation under strict regulations, the starting point is not tooling but defining clear audit and governance boundaries. Teams that treat governance as a phase two concern pay for it later, usually at the worst possible moment.
Regulated industries are not going to get simpler. Regulatory surface area tends to expand, not contract. A system designed with auditability as a first-class concern handles that expansion differently than one where compliance was retrofitted. The difference shows up not in normal operation, but in the moments that matter: an audit, an incident, a regulatory change that lands on a Friday afternoon. Build for those moments.