What are AI Agents, Their Use Cases, and How to Create One
An AI agent is an application that integrates one or more AI language models and implements a series of parameters to accomplish a specific end. Its usefulness depends on the model that powers it and also on what the developer who created it wants it to do. Hence, it is an ultra-personalized way of using language models: you can employ small language models for it, without losing accuracy and saving a lot of money on the process.
The biggest difference, then, between using a well-built AI agent and simply using APIs, such as ChatGPT’s, is that your experience will be more expensive and not as specialized. Building an AI agent will give you better results, as it is perfectly stitched to your project, while still saving you money, because it lets you use Small Language Models. Not only are they lighter to run locally by using some freely available Ollama-distributed models, but also their online APIs are way cheaper and faster to use.
Because of this, it is widely considered that AI Agents are the most efficient way of using artificial intelligence, as agents are quickly taking over the market. And you can learn everything about them here!
What (Really) is an AI Agent?
To begin with, we must dive a little further into what an agent is. It is a system, or rather a type of server, which integrates AI to receive a requisition, process it, and deliver a response. It also has the difference of remembering what was said previously, which can be used to better upgrade future responses, in what is called context span. And, to do this, you preset your AI model with instructions so that it knows how to properly parse your prompt, what to expect as input, and what you expect as output. You can also use its memory to modify a bit of its functioning in execution time, though it’s a bit of a bad practice, as we will discuss further.
As an AI agent, most of the time runs locally or on a personal server, and as it is hyper-specialized, you can also use Small Language Models. Not only do they have fewer parameters than their Large counterparts, but the great advantage is that they’re much lighter to run. So, with this, you can save tons of money in processing expenses and also guarantee that your results are more practical, as the model’s context span is smaller. Lastly, you can combine different SLMs in the same system so that it can fit a bigger suite of needs without consuming too much of your machine.
Also, AI agents can guarantee an incredibly higher accuracy level by implementing evaluation layers during their processing. That is, a model can run a prompt and generate a response, then run another prompt to test whether or not that is a valid response, and, if it is not, then it can try to get another response. Such agents can adjust their training data via memorization, understand how to better serve you, and then implement their conclusions – that’s why it is so powerful.
Those are some of the reasons why such types of scripts are certainly the best way to use the new era of artificial intelligence advancements. There’s no match between making a simple call to OpenAI’s API and making a request to an ultra-specialized AI agent, and that’s why mastering this technique is such an important thing currently.
Basic Architecture of an AI Agent
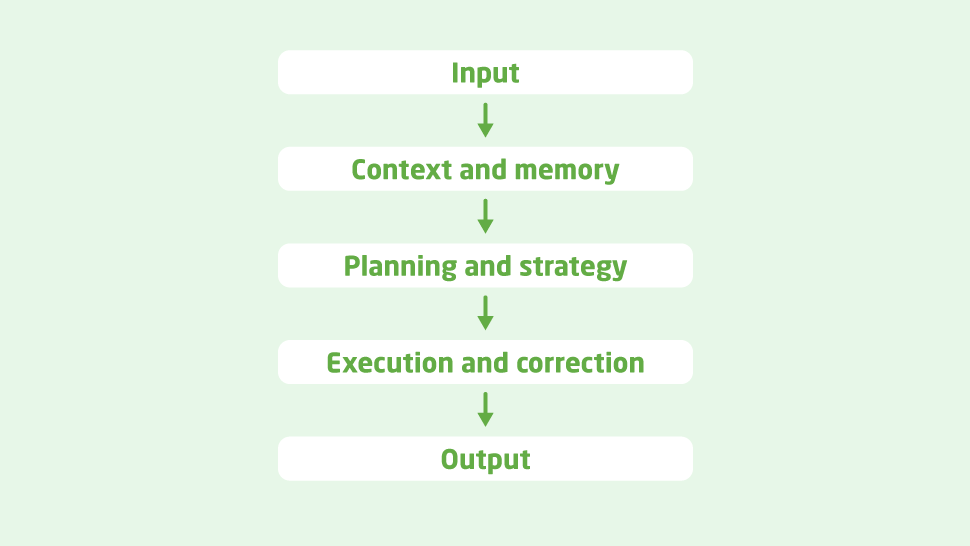
So, to put it into practice, let’s dive into the actual functioning of such an application, first studying the architecture of a simple agent and then how to implement it. To begin with, it has some layers, which we are going to understand a little better now:
- Input: That’s the simplest step in the architecture. The request from the user must come from the input layer. This input can come in many different forms, be it a direct call to the server API, or abstracted behind a front-end which features a chat and a clearer interface, etc.
- Context and Memory: That’s the layer in which the agent starts to comprehend what’ happening to personalize the language model to your needs. It will understand the context of your prompt and of the application itself, and also understand its memory and what it has already done, to process the data.
- Planning and Strategy: Is responsible for breaking down the process into different steps and creating a plan and a strategy for executing them. It can split the task into different sub-processes, for instance, to have it completed more efficiently. In another case, it can split a prompt to be processed by different models, that is, one part of it is parsed as text, and the rest is sent to another model to generate an image.
- Execution and Correction: It must execute what was planned previously to process the information and send the response back to the user. Also, the correction layer is responsible for making sure that the plan was actually followed and properly applied: if an error is found, then the program restarts its processing until success is reached. With this, the risk of hallucination is reduced tremendously, and the quality of your response will skyrocket: the agent will provide you exactly what you expect.
- Output: The same as the input, it is responsible for simply handing out the response in an appropriate way to be read and understood by the end user.
It can be summed up in this diagram:
Simple Implementation of an AI Agent with Python
Now, we will dive a bit into how to implement an AI agent. To do so, we will use Python, as it is the most common language used for everything related to artificial intelligence. Here’s the basic folder structure of the project:
agent/
├── agent.py
├── memory.py
├── planner.py
├── evaluator.py
├── preferences.py
├── llm.py
└── main.py- memory.py: This code creates a simple memory block based on an array, which is not the most optimized way to do it, even though it’s easy to understand. Also, it implements some methods, such as get_recent, which returns the five most recent memory blocks, and clear, which clears the history.
# memory.py
class Memory:
def __init__(self):
self.history = []
def add(self, message: str, role: str = "user"):
self.history.append({"role": role, "content": message})
def get_recent(self, n=5):
return self.history[-n:]
def clear(self):
self.history = []- preferences.py: It implements a preset to get your preferences so that you don’t have to configure it many times across your code. The purpose is mostly focused on the Don’t Repeat Yourself principle.
# preferences.py
class UserPreferences:
def __init__(self, style="formal", language="en", verbosity="medium"):
self.style = style
self.language = language
self.verbosity = verbosity
def to_prompt_instruction(self):
return f"Respond in a {self.style} style, in {self.language}, with {self.verbosity} verbosity."- planner.py: Implements the logic to create different plans according to the prompt. This one is very simple, but can reach as far as to diverge into different language models, such as generate an image or video instead of text, for instance. It can, then, implement what we perceive as a multimodal agent. It can also detect prompts that are prone to repeat a lot, such as “thank you”, and deliver default responses.
# planner.py
class Planner:
def create_plan(self, user_input: str):
if "summary" in user_input.lower():
return ["Extract key ideas", "Write summarized paragraphs"]
elif "code" in user_input.lower():
return ["Analyze requirements", "Write code", "Test and verify"]
else:
return ["Understand request", "Generate direct response"]- evaluator.py: Creates the guardrail to test if the response is valid or not. In this example, it just tests if the response from the language model is only too long or too short.
# evaluator.py
class Evaluator:
def evaluate(self, output: str):
# Example of basic heuristics (could also call an LLM for deeper critique)
if "error" in output.lower():
return "Needs correction"
elif len(output) < 20:
return "Too short"
return "Acceptable"- llm.py: That’s the layer that effectively runs the prompt in the language model. In this example, we’re using OpenAI’s API and Python library.
# llm.py
import openai
class LLM:
def __init__(self, model="gpt-4"):
self.model = model
def ask(self, messages):
response = openai.ChatCompletion.create(
model=self.model,
messages=messages,
temperature=0.7,
max_tokens=512
)
return response.choices[0].message["content"]- agent.py: It basically unites everything together in a single class to properly function.
# agent.py
from memory import Memory
from preferences import UserPreferences
from planner import Planner
from evaluator import Evaluator
from llm import LLM
class IntelligentAgent:
def __init__(self):
self.memory = Memory()
self.preferences = UserPreferences()
self.planner = Planner()
self.evaluator = Evaluator()
self.llm = LLM()
def handle_input(self, user_input: str):
self.memory.add(user_input, role="user")
plan = self.planner.create_plan(user_input)
instruction = self.preferences.to_prompt_instruction()
context = self.memory.get_recent()
messages = [{"role": "system", "content": instruction}]
messages += context
messages.append({"role": "user", "content": f"Plan: {plan}\n{user_input}"})
response = self.llm.ask(messages)
evaluation = self.evaluator.evaluate(response)
self.memory.add(response, role="assistant")
print("🔄 Response evaluation:", evaluation)
return response- main.py: That’s the class that actually implements everything. That’s the most basic way to implement the agent, as it runs directly in the terminal with user input, but the most usual way to do it is with a REST API. It can be done in Python with the FastAPI or Flask frameworks.
# main.py
from agent import IntelligentAgent
if __name__ == "__main__":
agent = IntelligentAgent()
while True:
user_input = input("👤 You: ")
if user_input.lower() in ["exit", "quit"]:
break
output = agent.handle_input(user_input)
print("🤖 Agent:", output)Fine-Tuning vs. Prompt Engineering: What’s best for your use case?
Another very important use case for an AI model is to fine-tune it for your specific use case. So, it is important to explain the difference between the fine-tuning process and just doing improvements on the prompt for the language model your agent uses.
So, fine-tuning is the process of altering the training data of the model with your information, hence partially retraining it. It is, then, a means of modifying the results of the model, fine-tuning it to better fit your needs and use case. But, if you’re thinking about using it, you must bear in mind that it is extremely computer-intensive and it will have a cost on your expenses. Also, as it is somewhat complex to do, and you must first of all have lots of well-structured and organized data, it’s in the vast majority of cases not worth the effort.
So, in such circumstances, it is best to resort to prompt engineering. It is the good practices and the techniques employed to get the best results possible from a single prompt. Sometimes it can be the simple practice of better describing what you’re submitting, the persona that the LM must use, and what you expect in response. But there are also some parameters you can send in your prompt, such as:
- Temperature: ranges from 0 to 1 and expresses how random the results you’re expecting from the model
- max_tokens: the maximum size in tokens of your expected response
- presence_penalty and presence_quality: range from -2 to 2 to express how much you desire to repeat matters and words that have been discussed previously
With all of this, you can control to the detail what exactly you’re expecting from the language model, hence making sure you’re extracting 100% from it.
Conclusion
So, to sum everything up, creating agents is certainly the most efficient way to use recent advancements in the AI environment. It’s cheaper, more resilient, and fine-tuned to your needs, and can allow you to escape big expenses with other models such as ChatGPT or Claude. Also, as it will run on your machine or a server owned by you, the data will be ours, free of tracking and entirely in your hands to manage. You can also review the best AI tools directory
Also, as it is a service in your hands to code, you can keep improving it, allowing it to have more memory, a larger context span, and allow it to take more actions, etc. Hence, quite literally, the codebase is yours to upgrade, and it can do whatever you want it to. Think, for instance, that you can turn it into a multimodal program: generate images, interpret many different input types, etc. The sky is, quite literally, the limit, as you can upgrade it to the extent of your needs.
And, in case you want an AI agent tailored to your use case, made with top-tier technologies and running as efficiently as possible, make sure to contact us at Chudovo. We are a consultancy focused on delivering top-notch software in many different areas, having delivered many advanced AI/ML projects. Schedule a meeting with us, and let’s see the best way to automate your company’s processes and make it more efficient and profitable than ever!